

파일 드래그앤 드롭하면 됩니다
나중에 PPT 만들 때 쓰기 편하게 캡쳐본 모아둬요
1. 기온 데이터
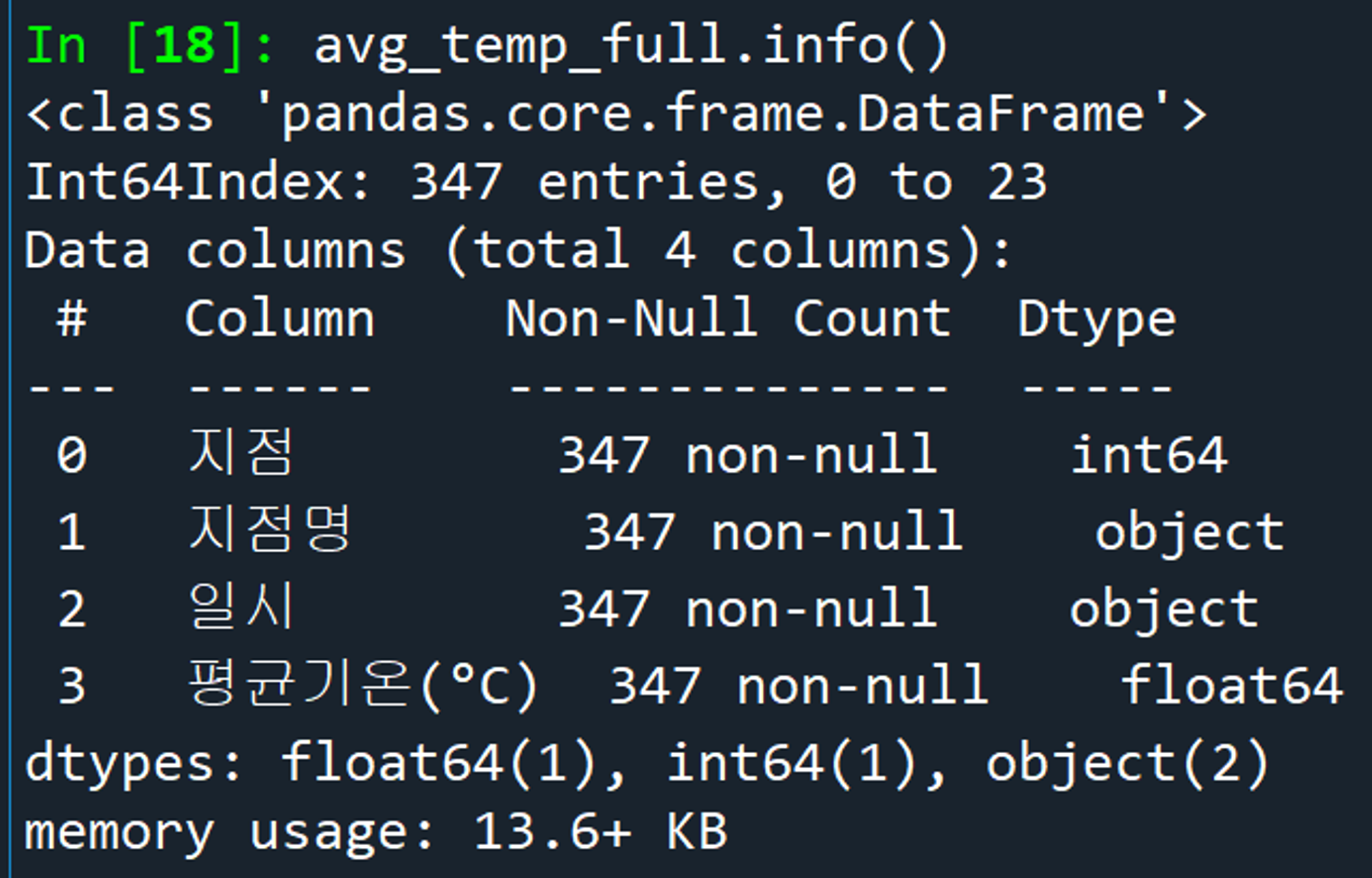
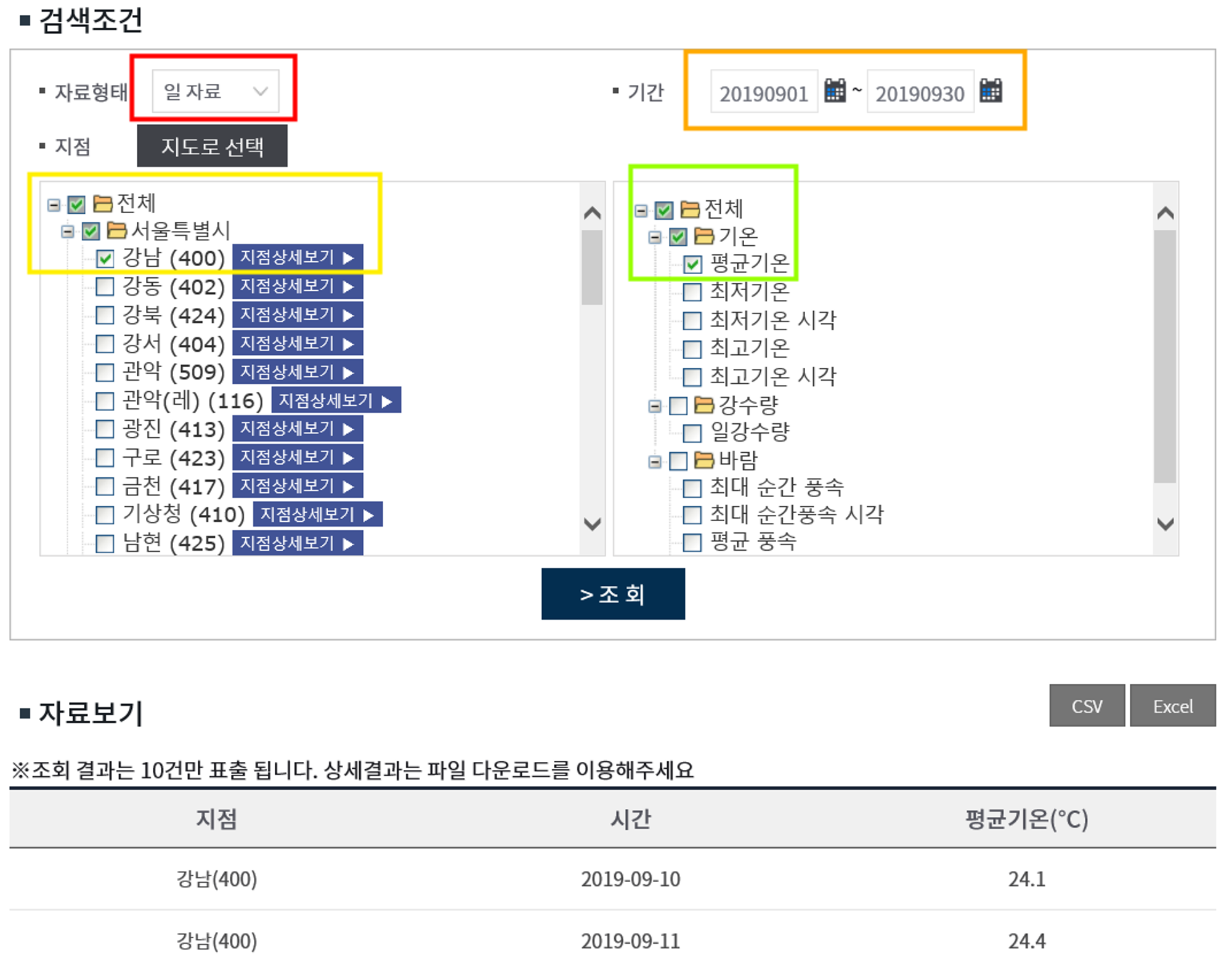
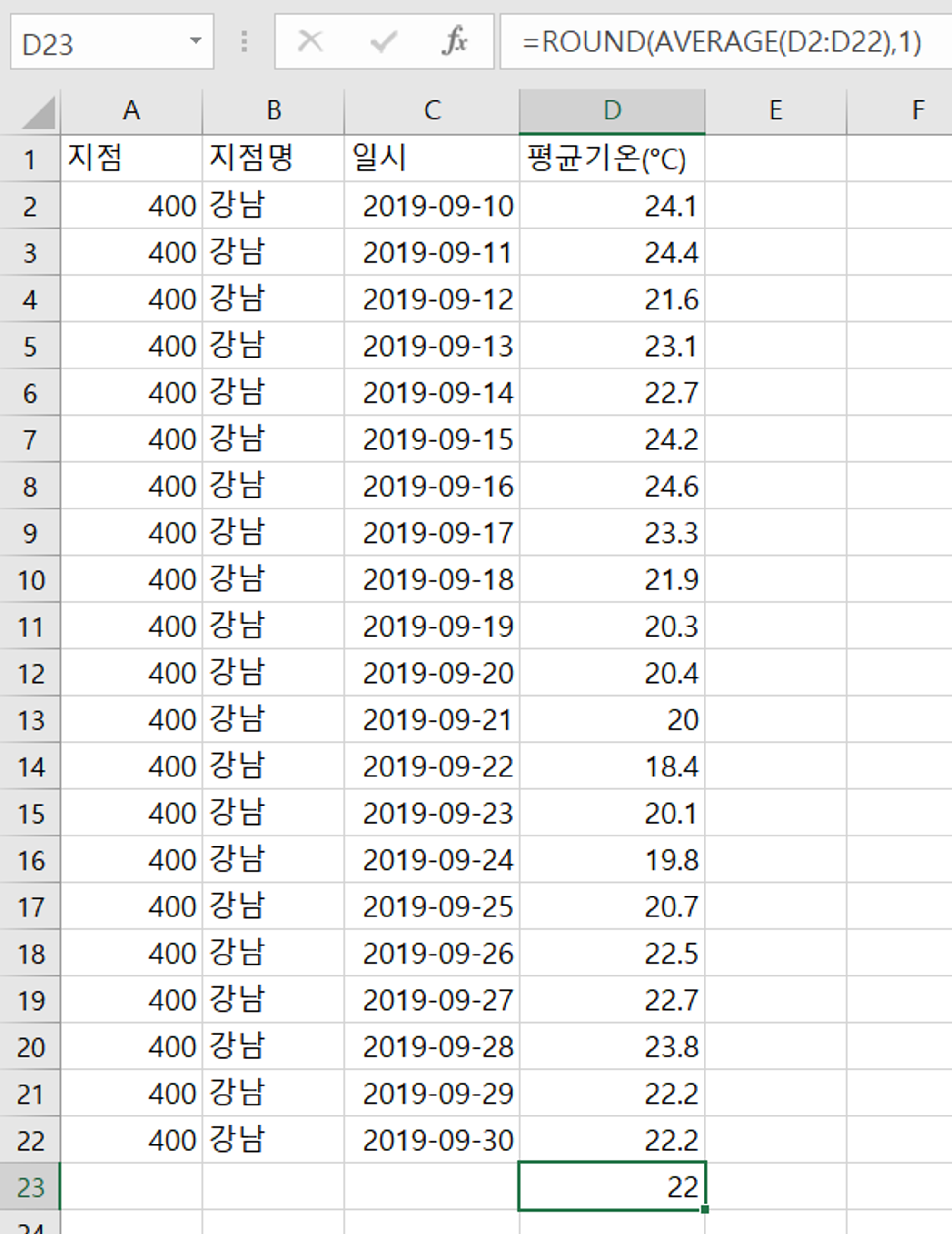
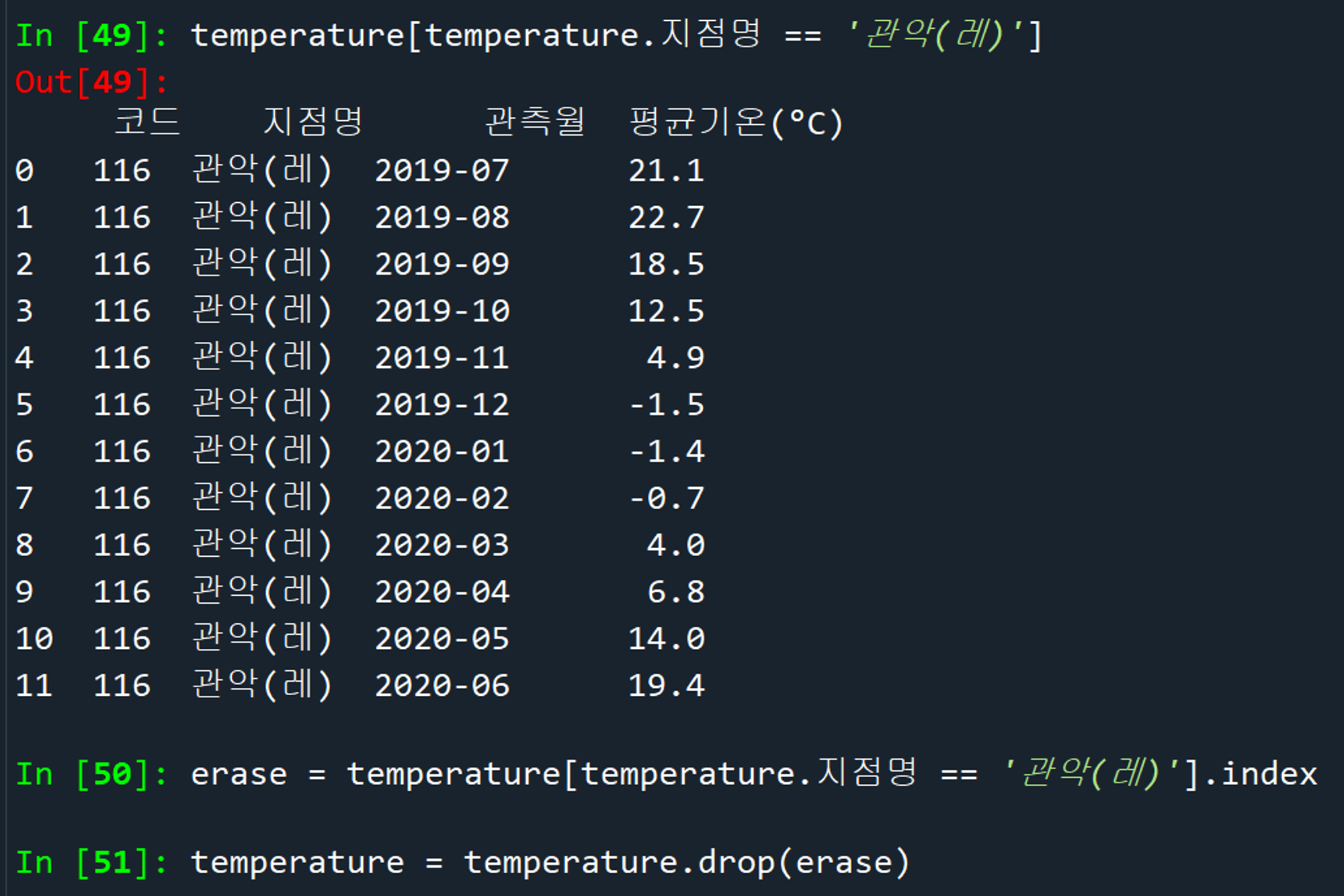
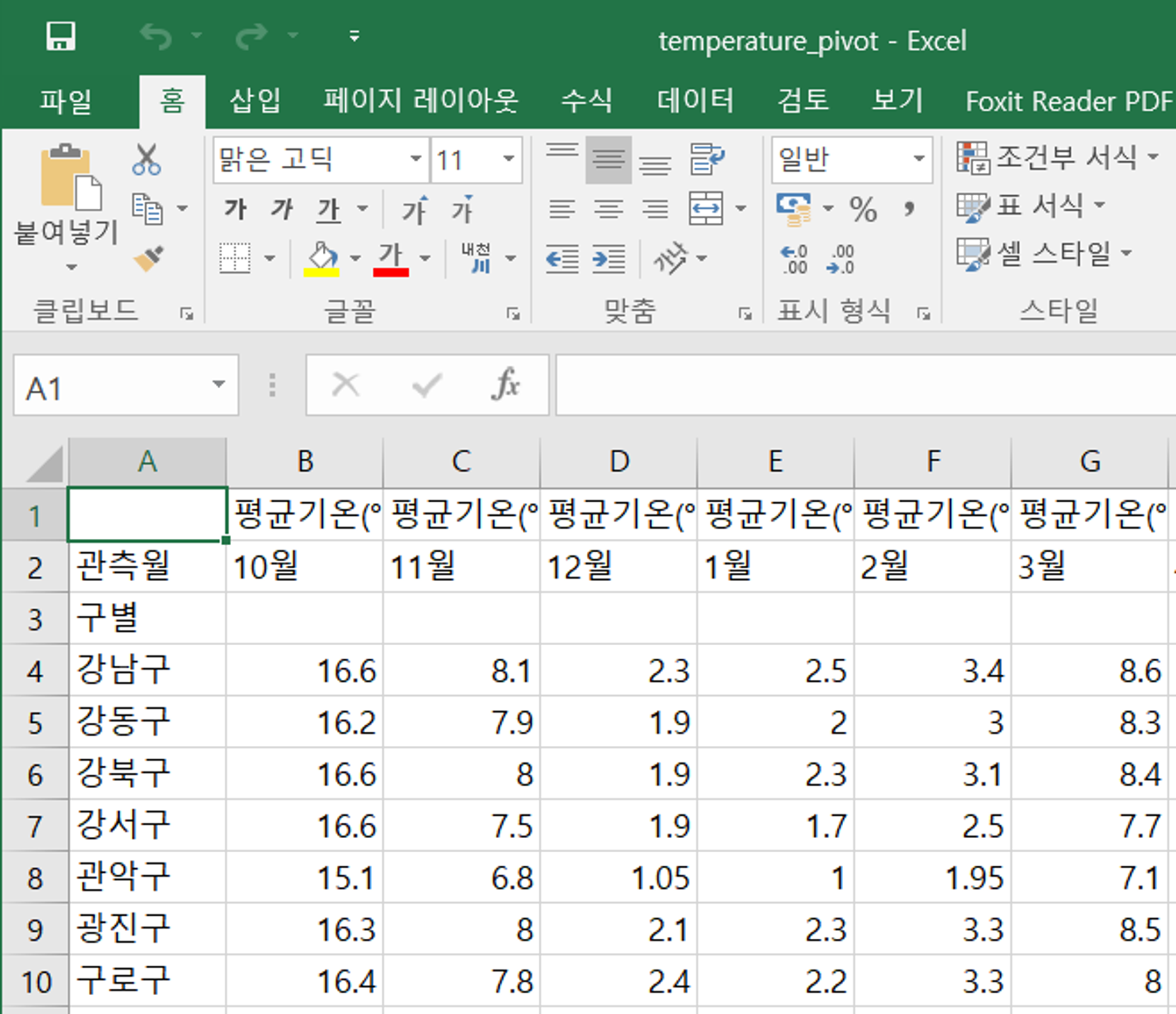
파이썬 피벗에서는 1~12월 순으로 정렬되는게 아니라, 10월에서의 1 뒤에 위치한 0을 우선으로 인식하는지 10~12월이 이 먼저 나오네요. 1월부터 나오도록 따로 정렬해 둔 파일은 tp_final_2.csv 입니다.
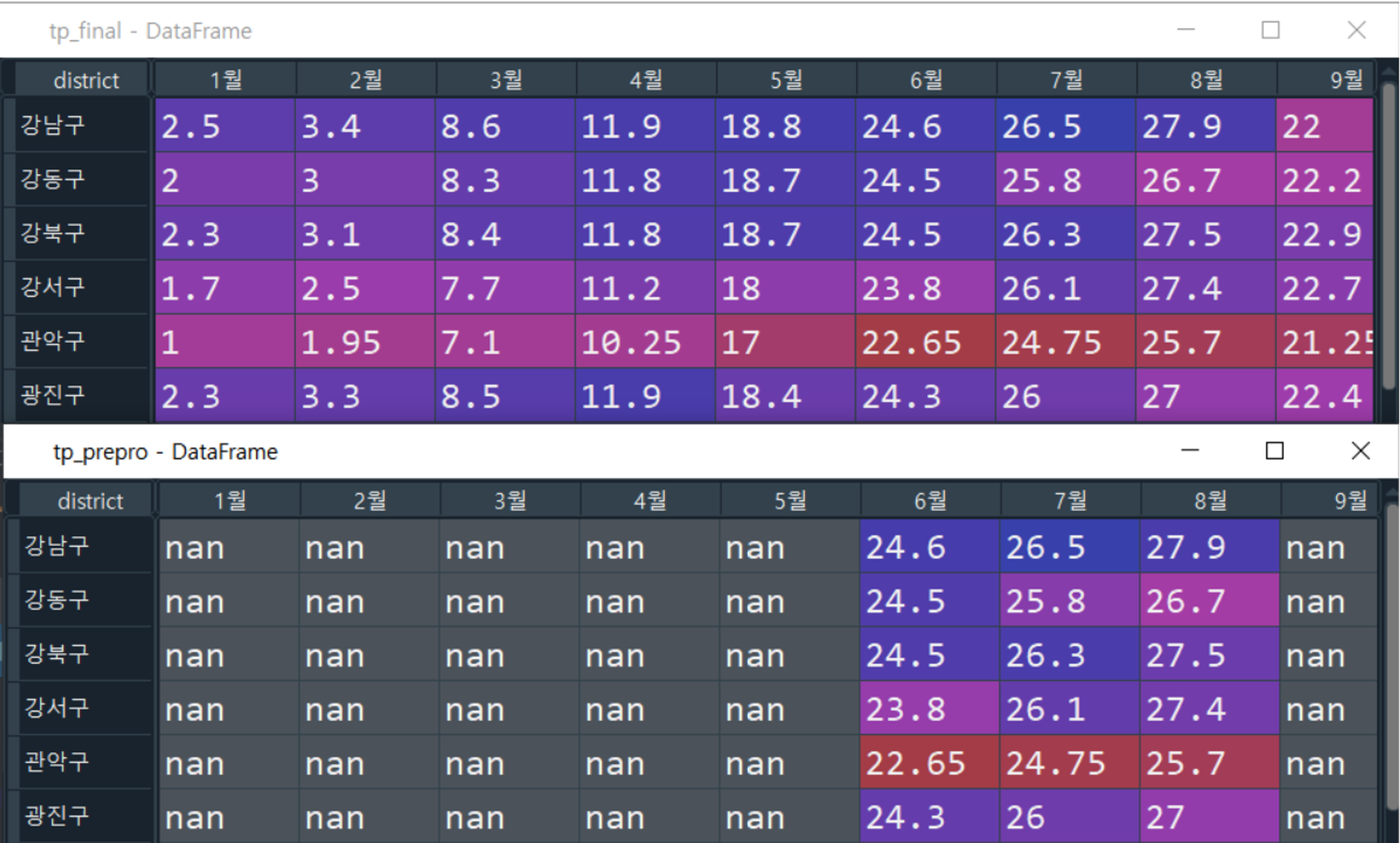
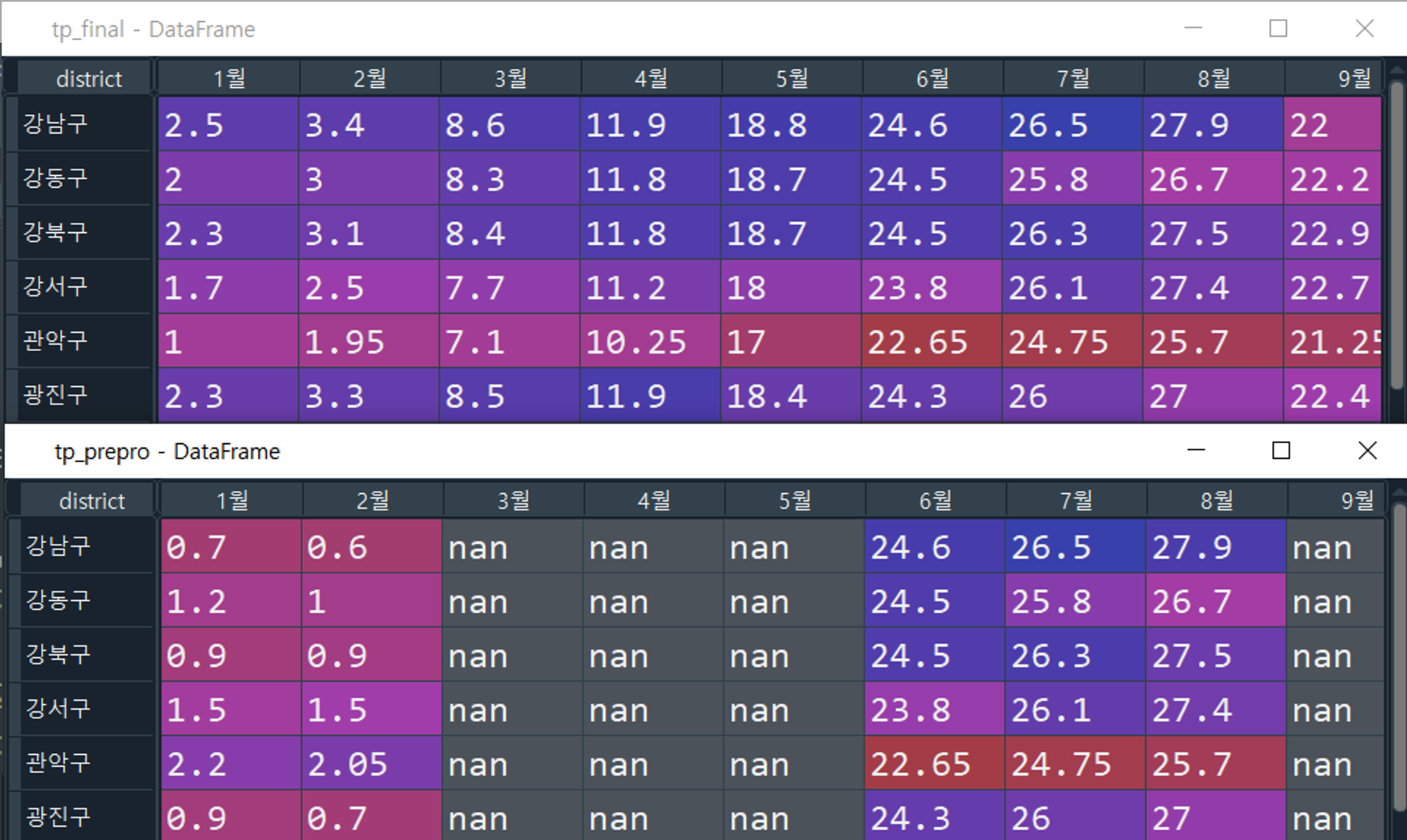
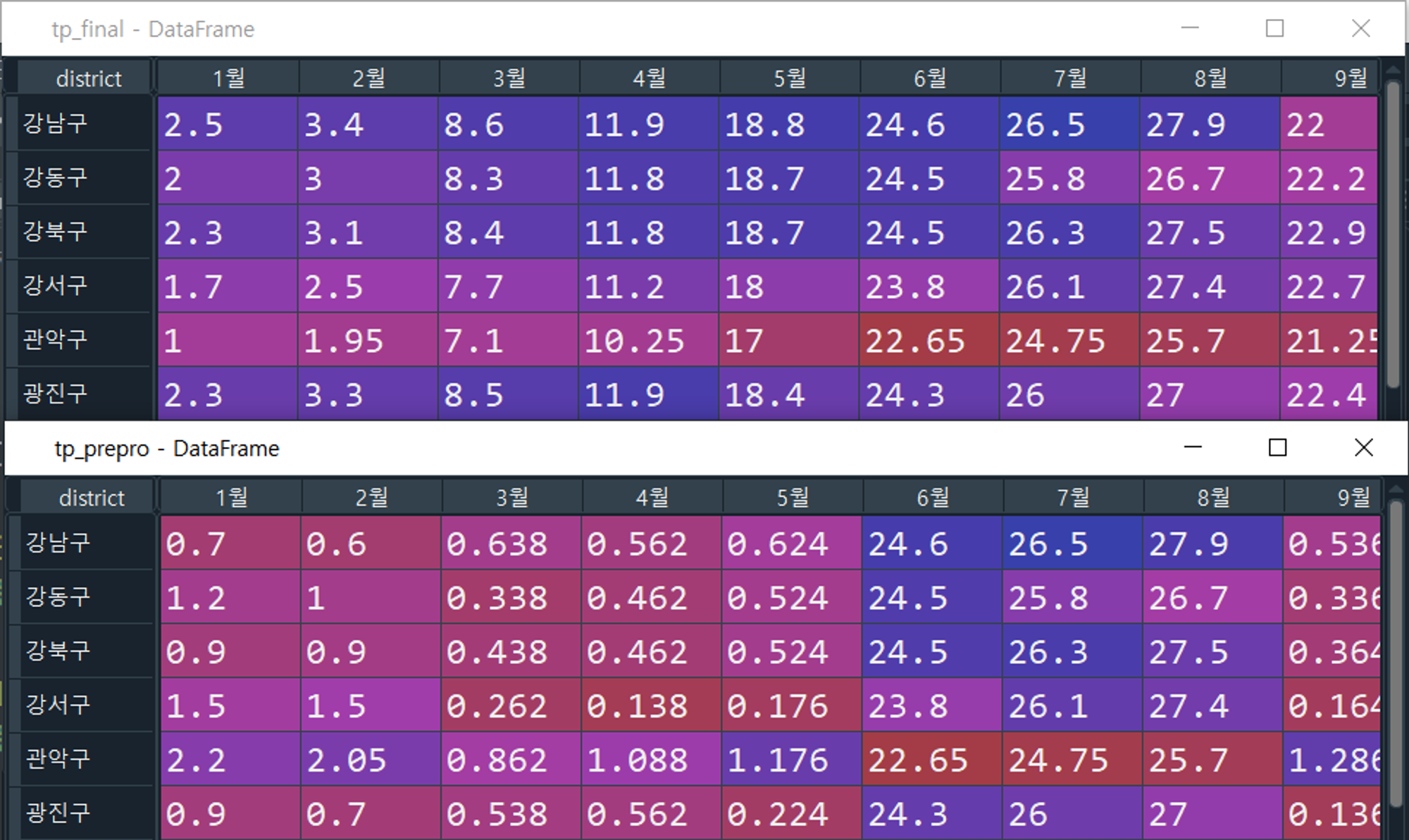
전처리 이후 정규화까지 완료된 최종 파일입니다. 바로 지도에 사용하면 돼요. (정규화→점수부여 방식이 아니라, 최대한 규칙에 맞도록 계절별 전처리→정규화 순서로 진행했기 때문에 파일은 하나 밖에 없습니다)
2. 강수량 데이터
.png&blockId=2b114fdf-165c-49d7-9e8f-a6f110eb2b75)
월강수량 정보 다운로드 (해당 자료의 경우 2개 초과하여 다운로드 받을 경우 아래쪽 행이 잘려버림)
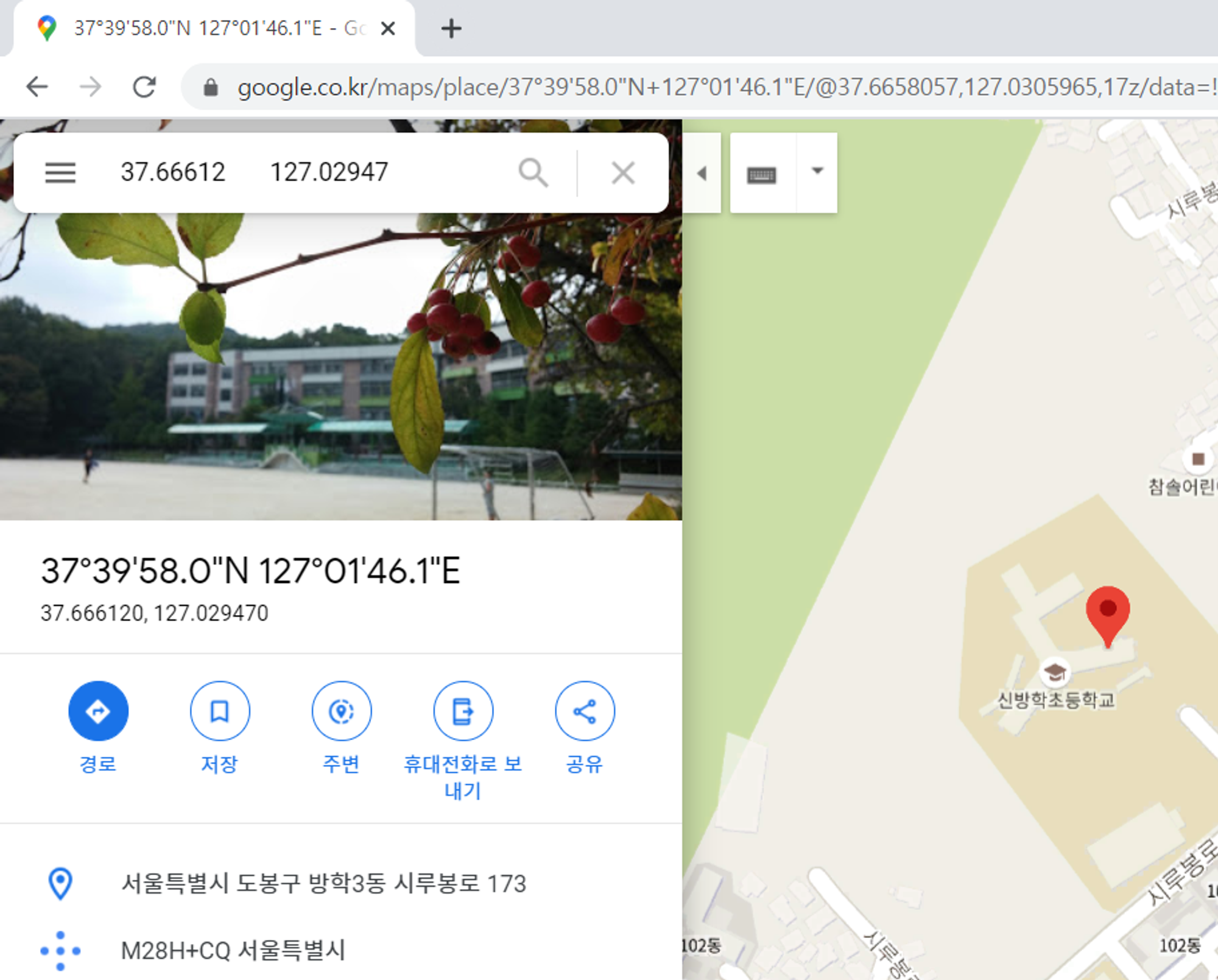
측정소 위도, 경도 정보를 통한 주소 찾기
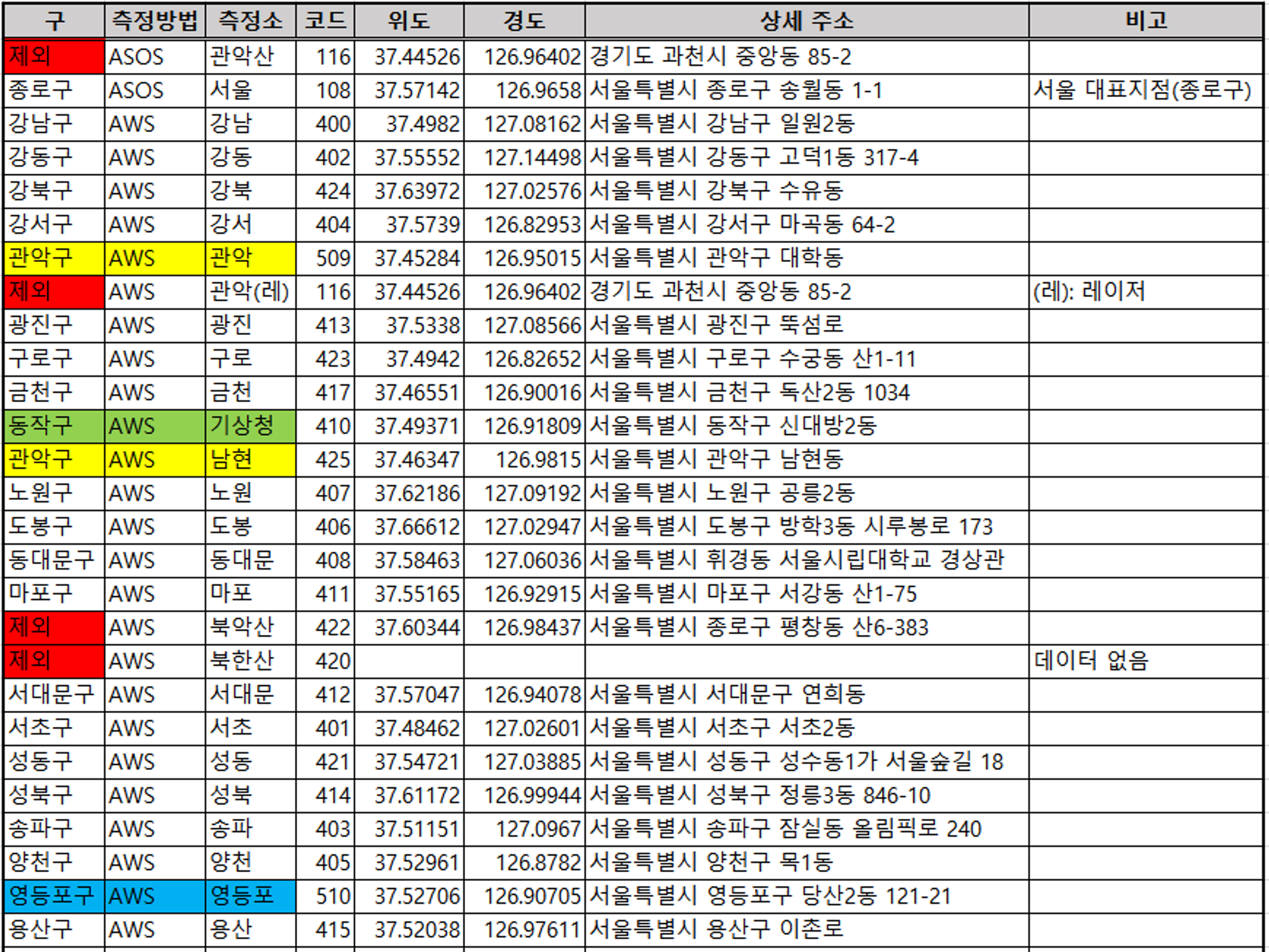
측정소가 위치한 구 정리, 결측 및 중복값 파악

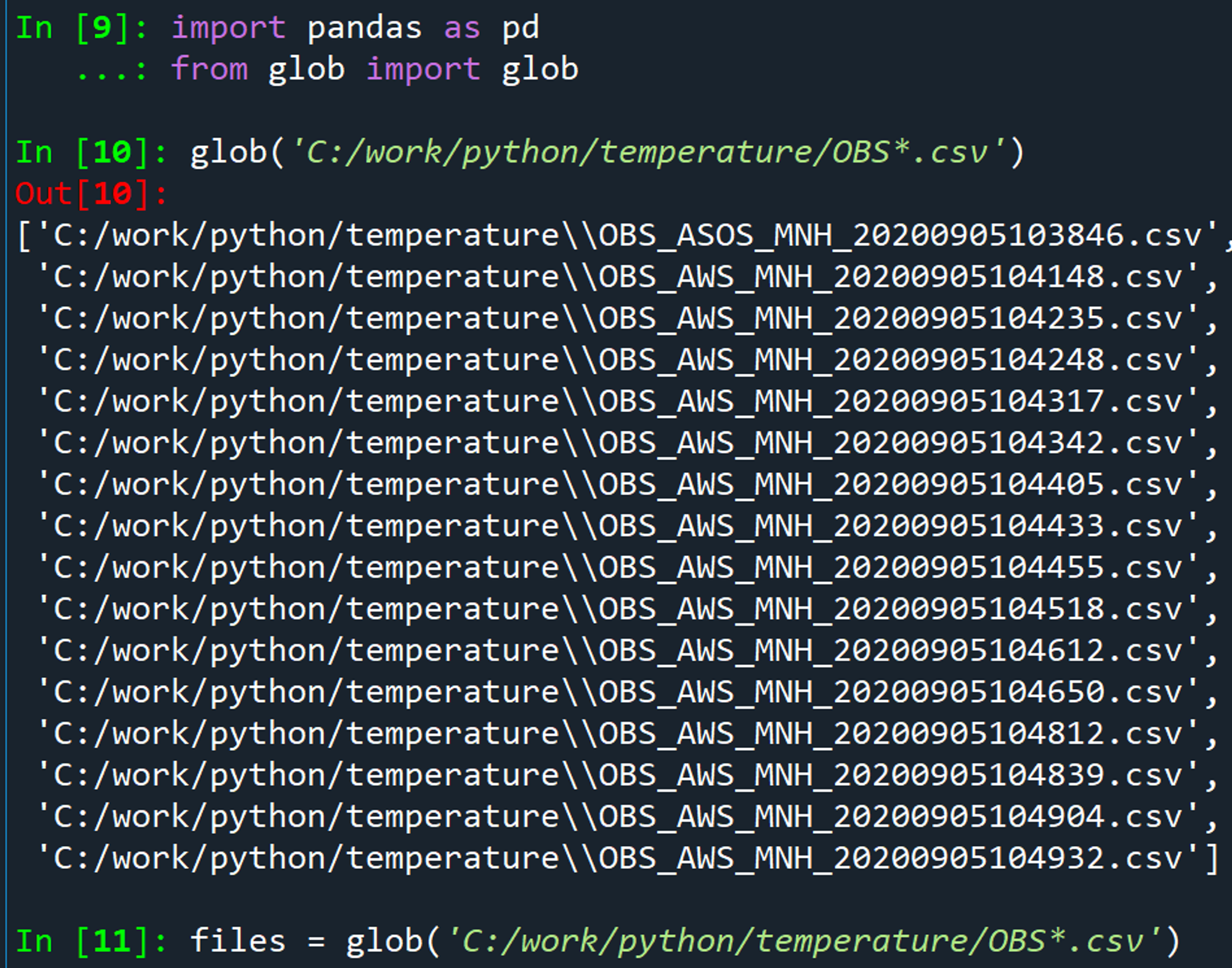
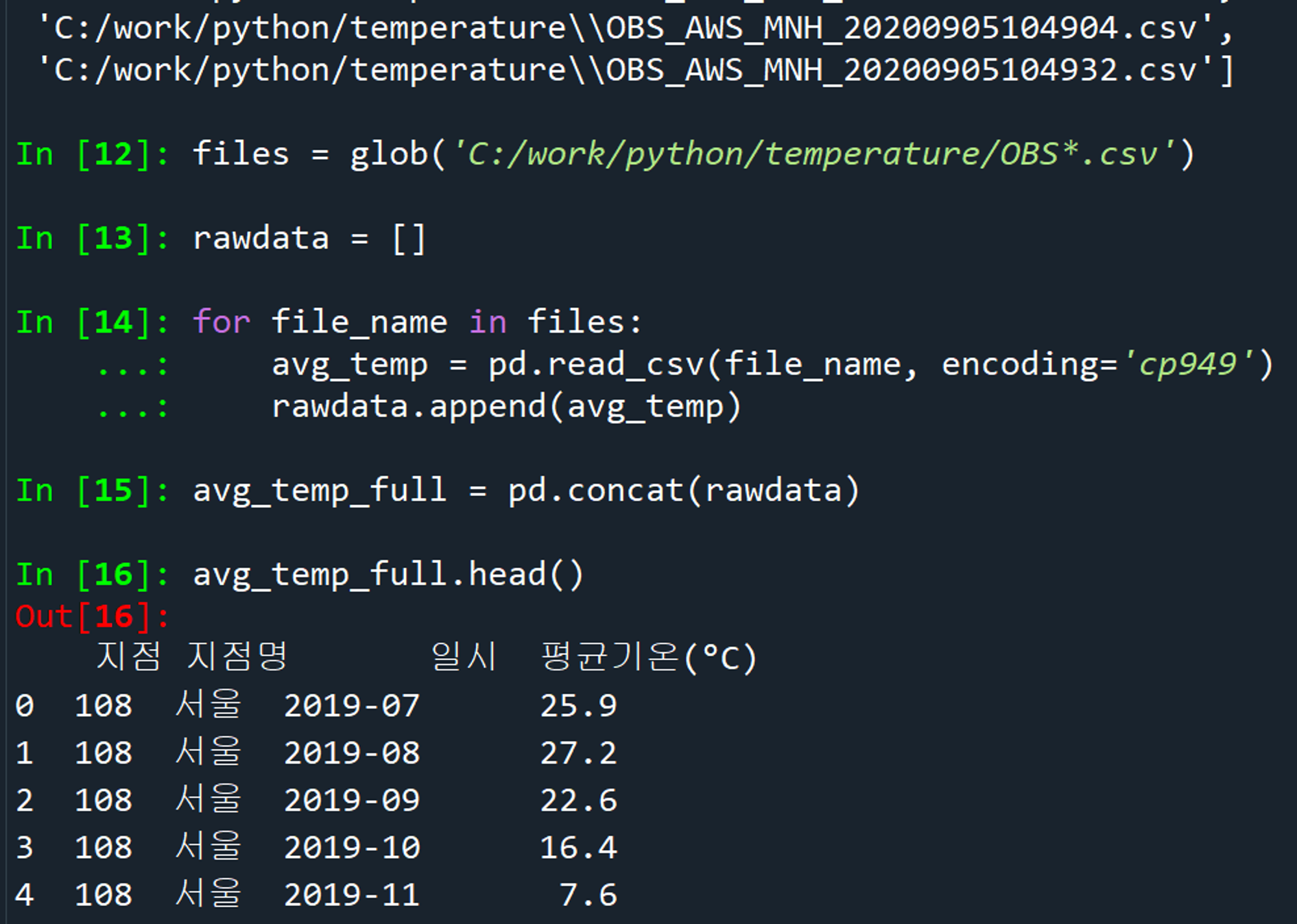
이름 형식이 동일한 AWS 15개 파일 먼저 병합해 봄. ASOS 1개는 따로 작업해줘야 함. 빼먹지 말기!!
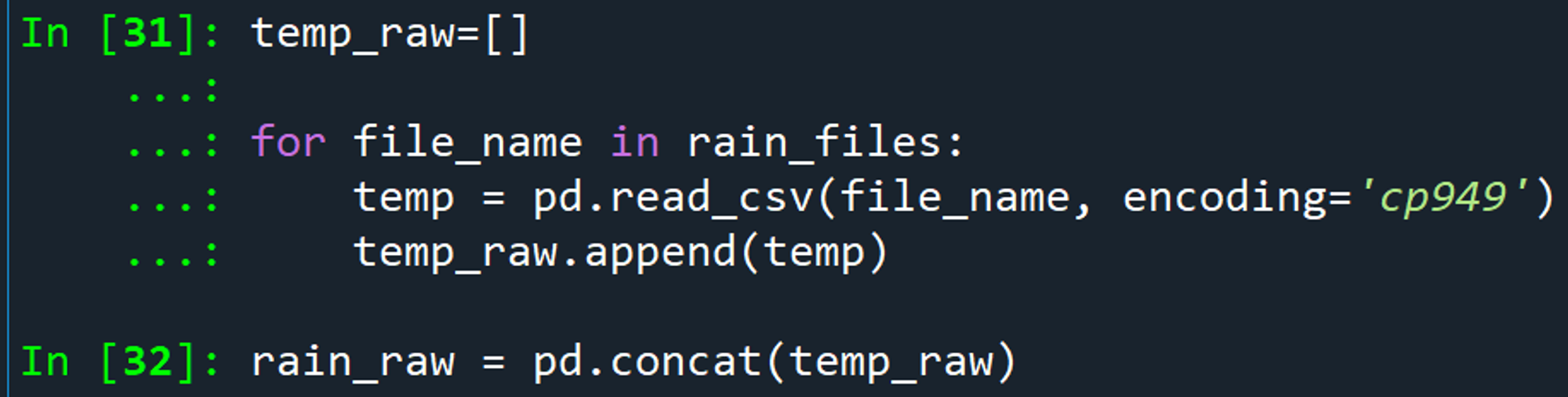
많은 에러 끝에, cp949로 인코딩을 통해 성공~!!
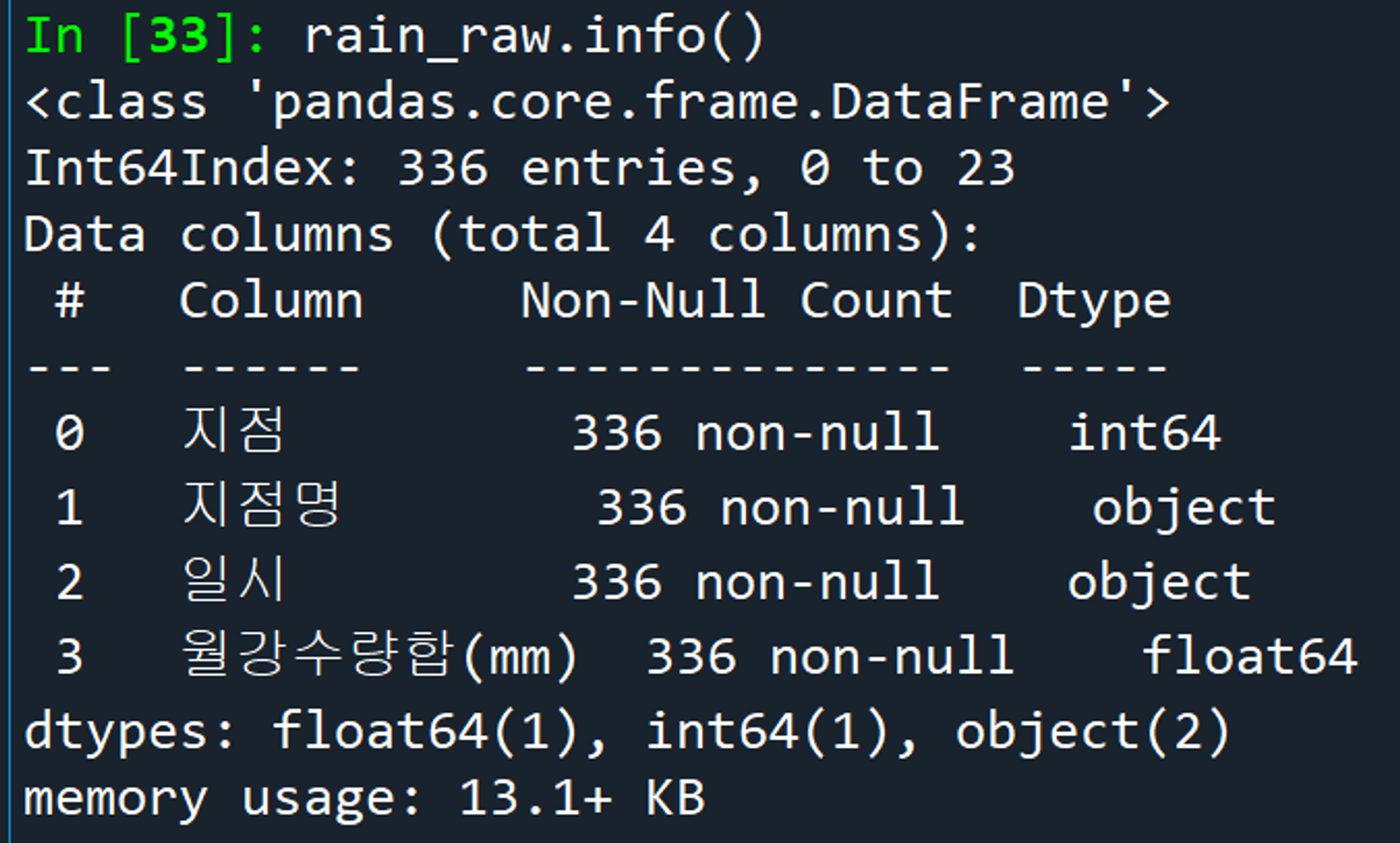
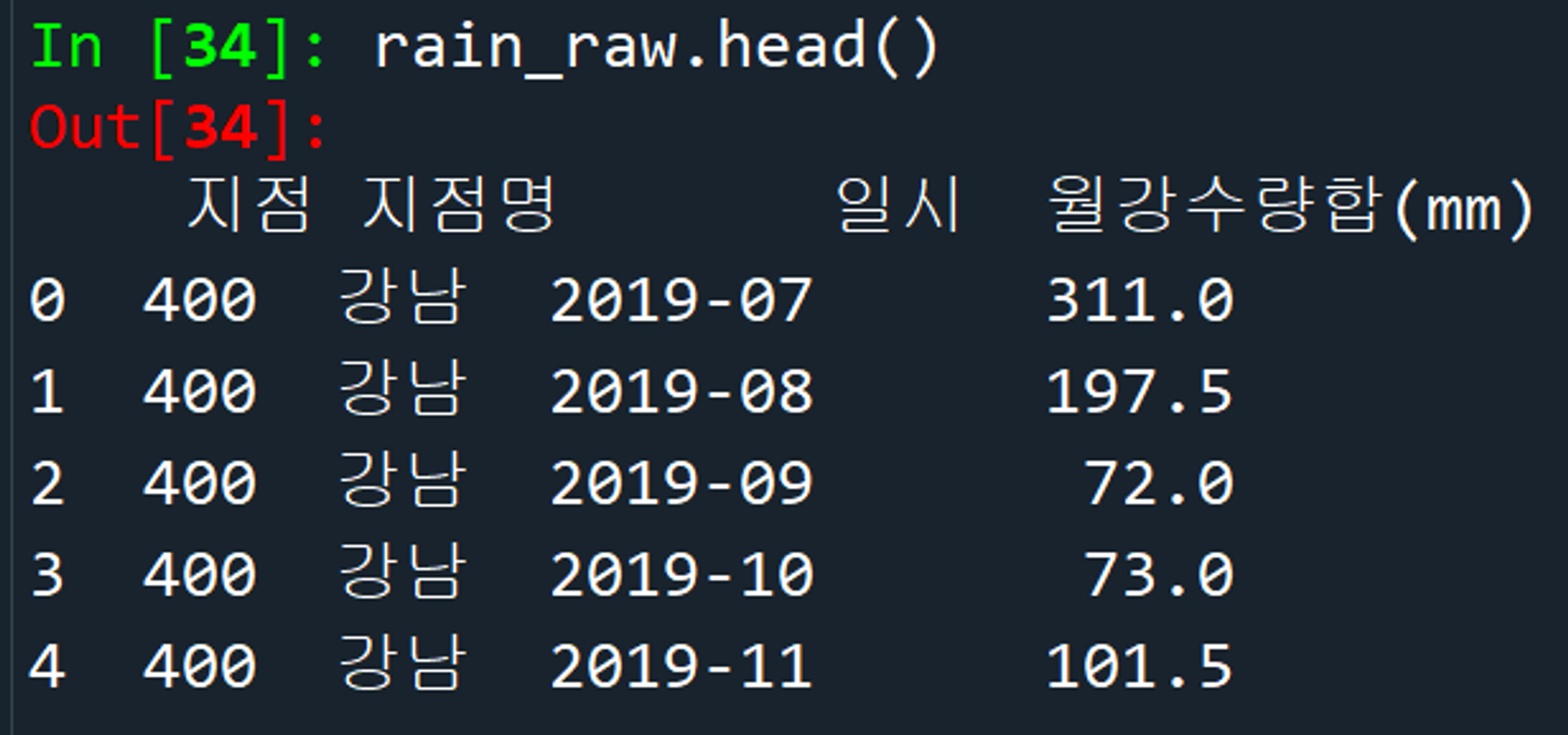
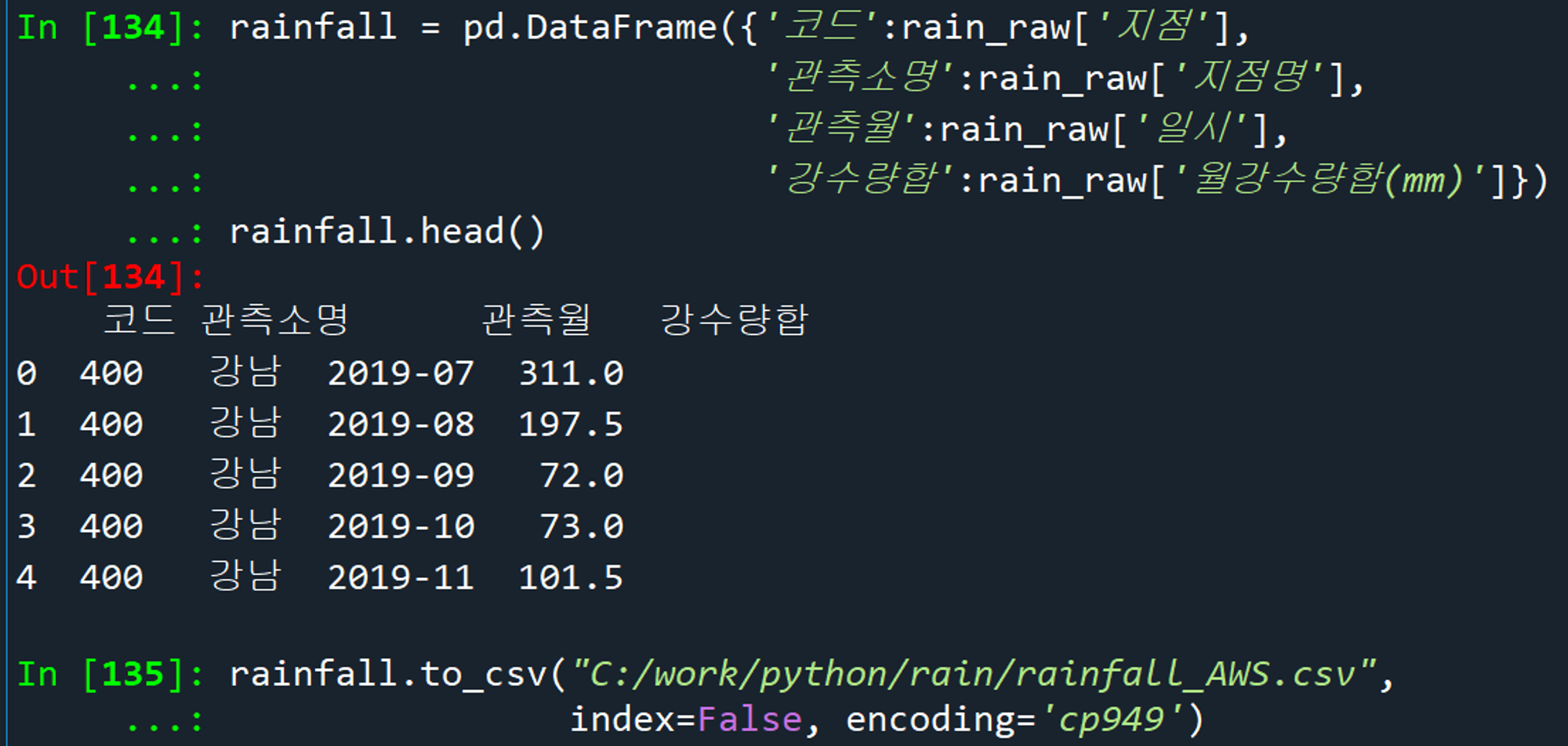
데이터프레임_열이름변경_csv저장
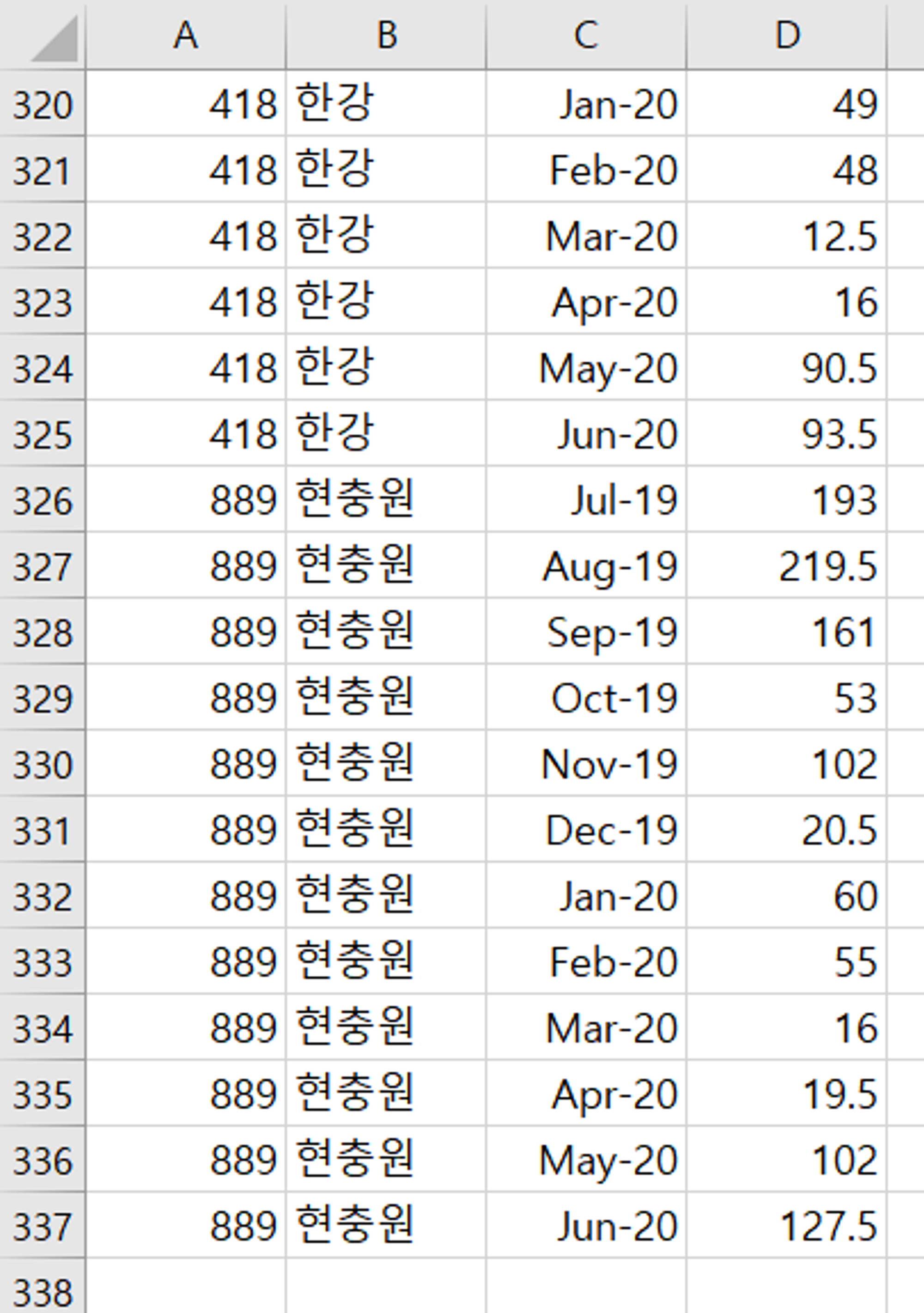
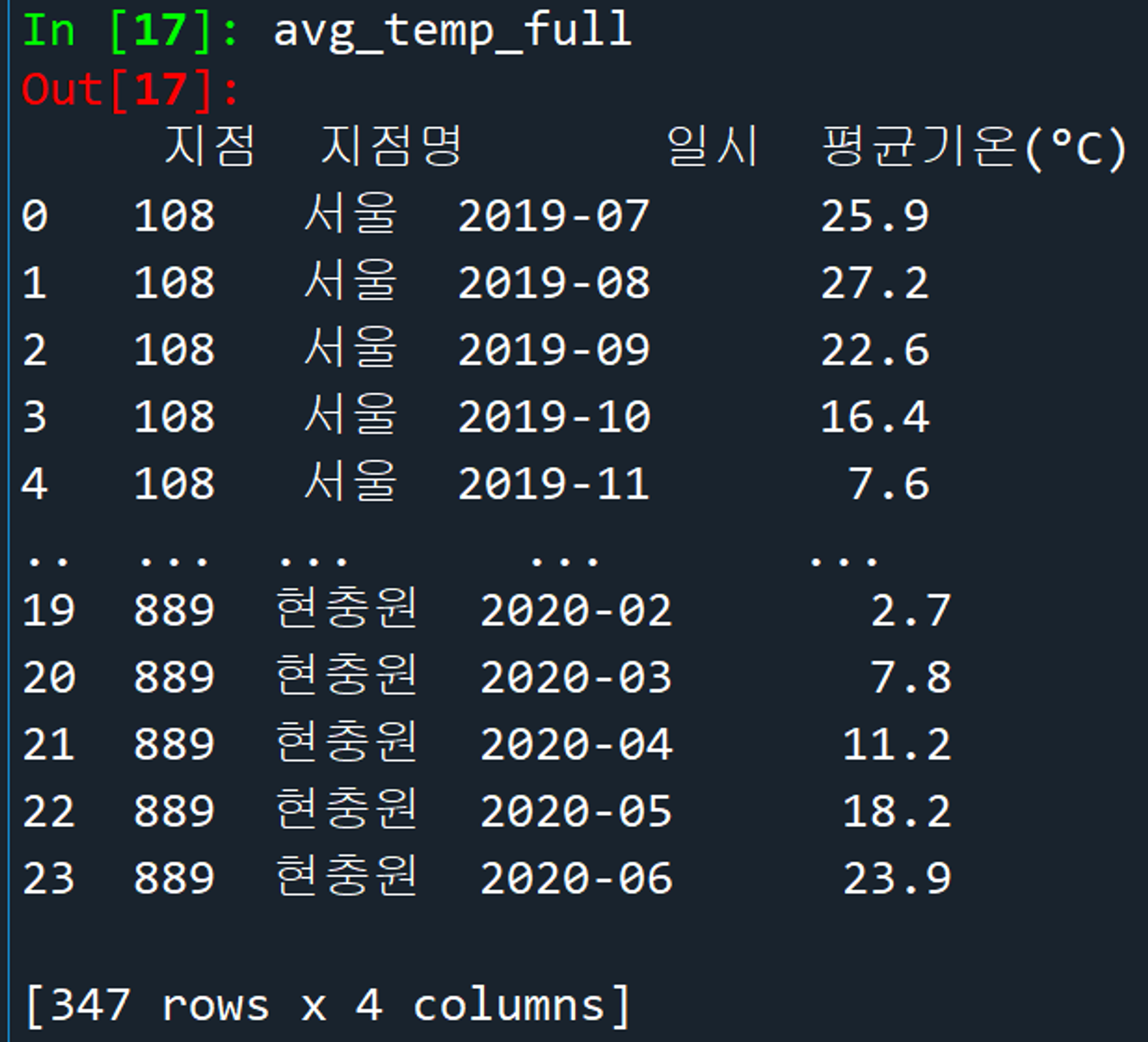
누락 없이 336개 데이터 저장 완료
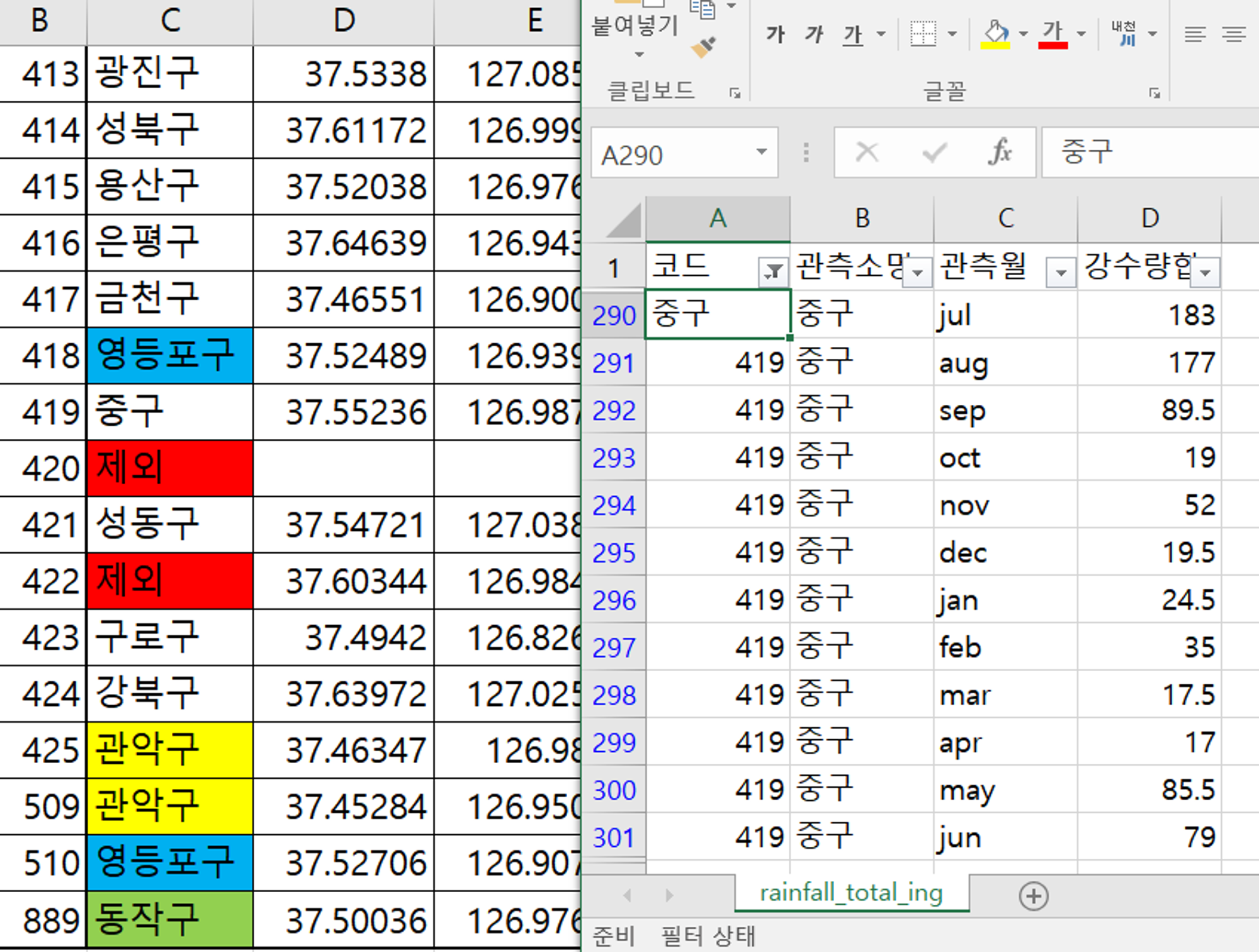
엑셀 필터 활용하여 코드명을 소속 구 이름으로 변경
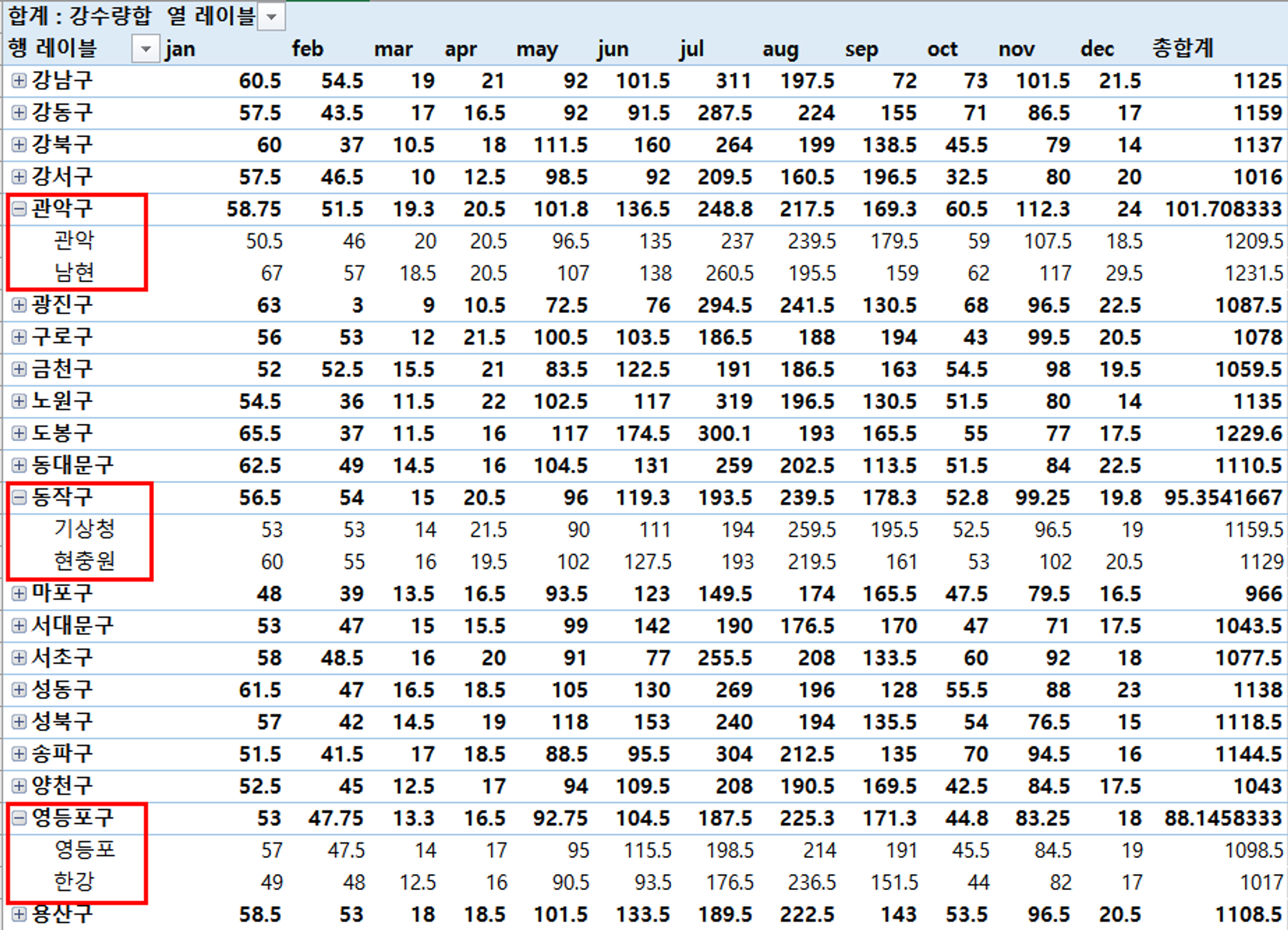
피벗 테이블 활용하여 재정렬 / 중복되는 구의 값을 평균 처리
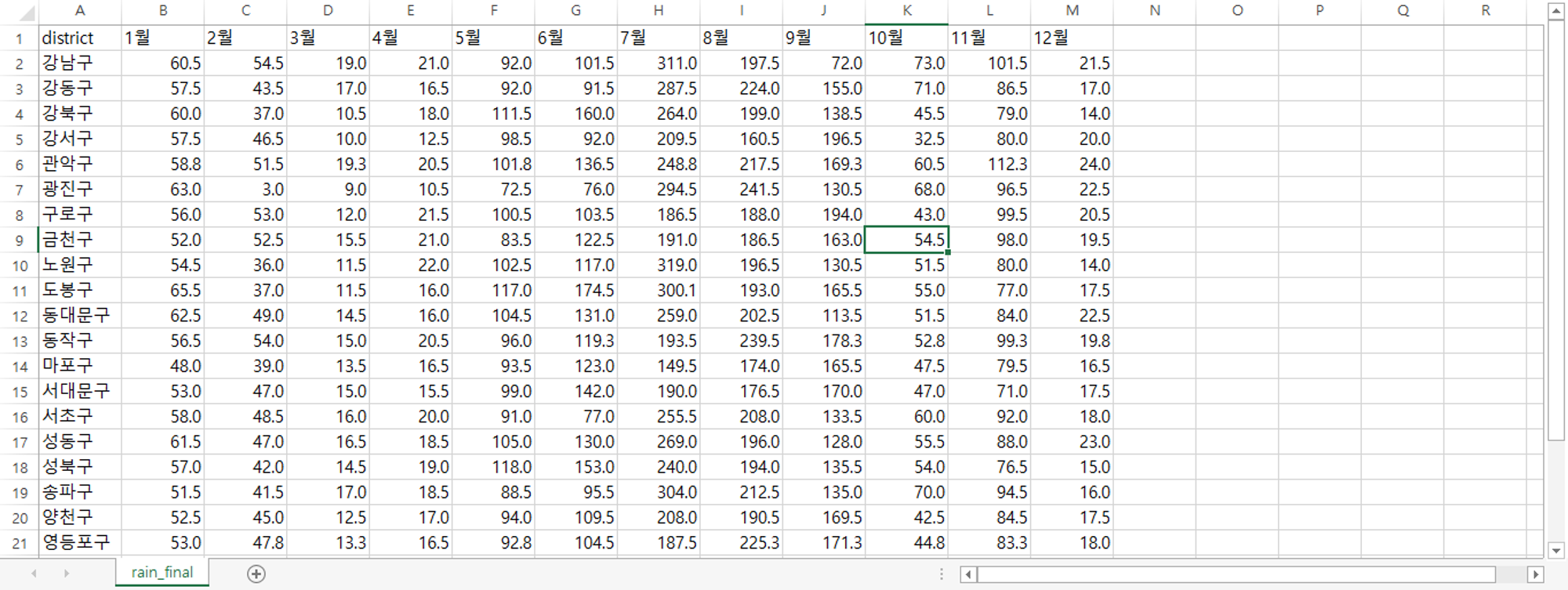
최종 전처리 완료된 구별 강수량 파일
3. 대기오염도 데이터
미세먼지 단위 :
초미세먼지 단위 :
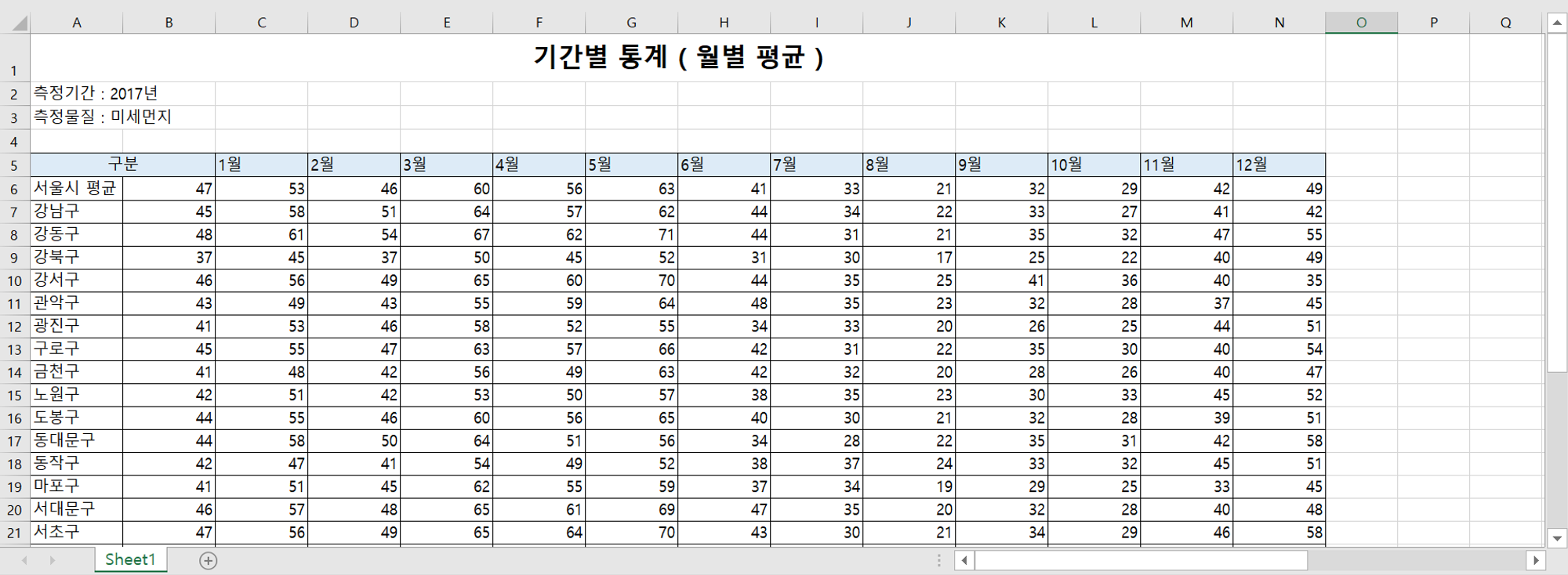
미세먼지_raw
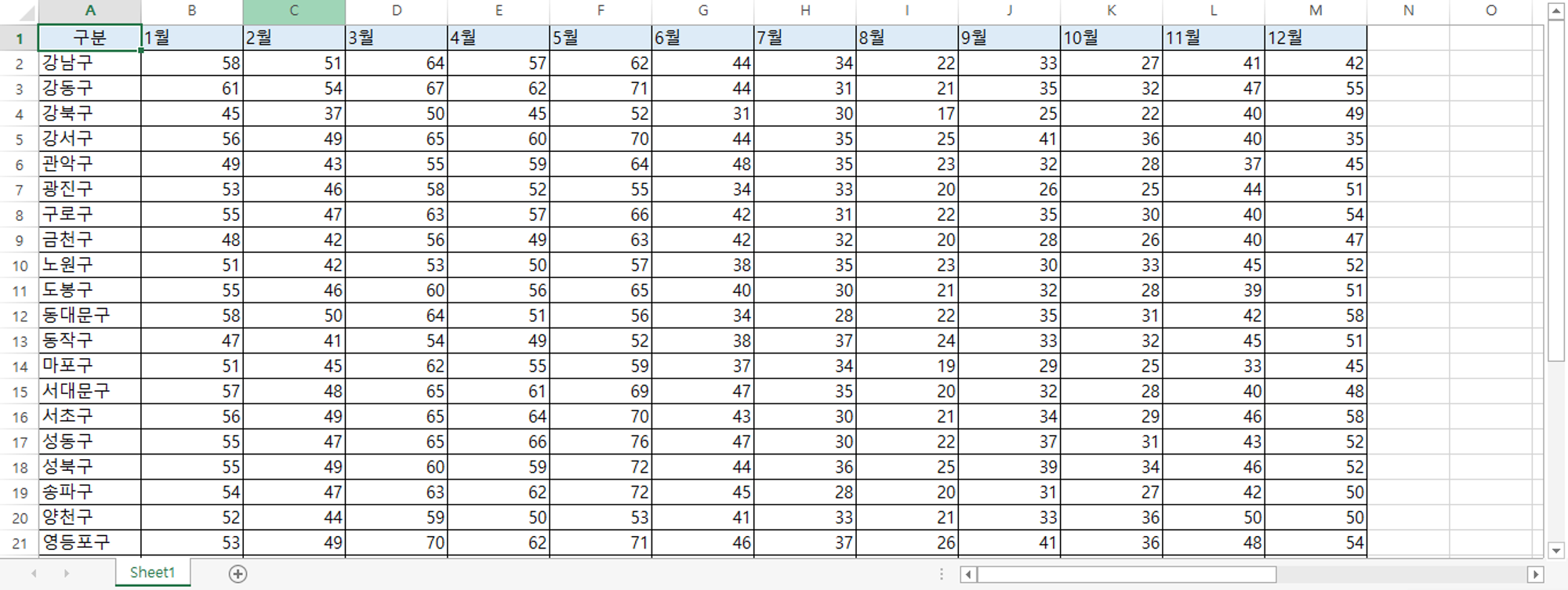
미세먼지_불필요 행 제거
R에서 숫자로 시작하는 열은 인식 못하므로 영어로 열 변경
초미세먼지_raw
초미세먼지_불필요행 제거
R에서 숫자로 시작하는 열은 인식 못하므로 영어로 열 변경
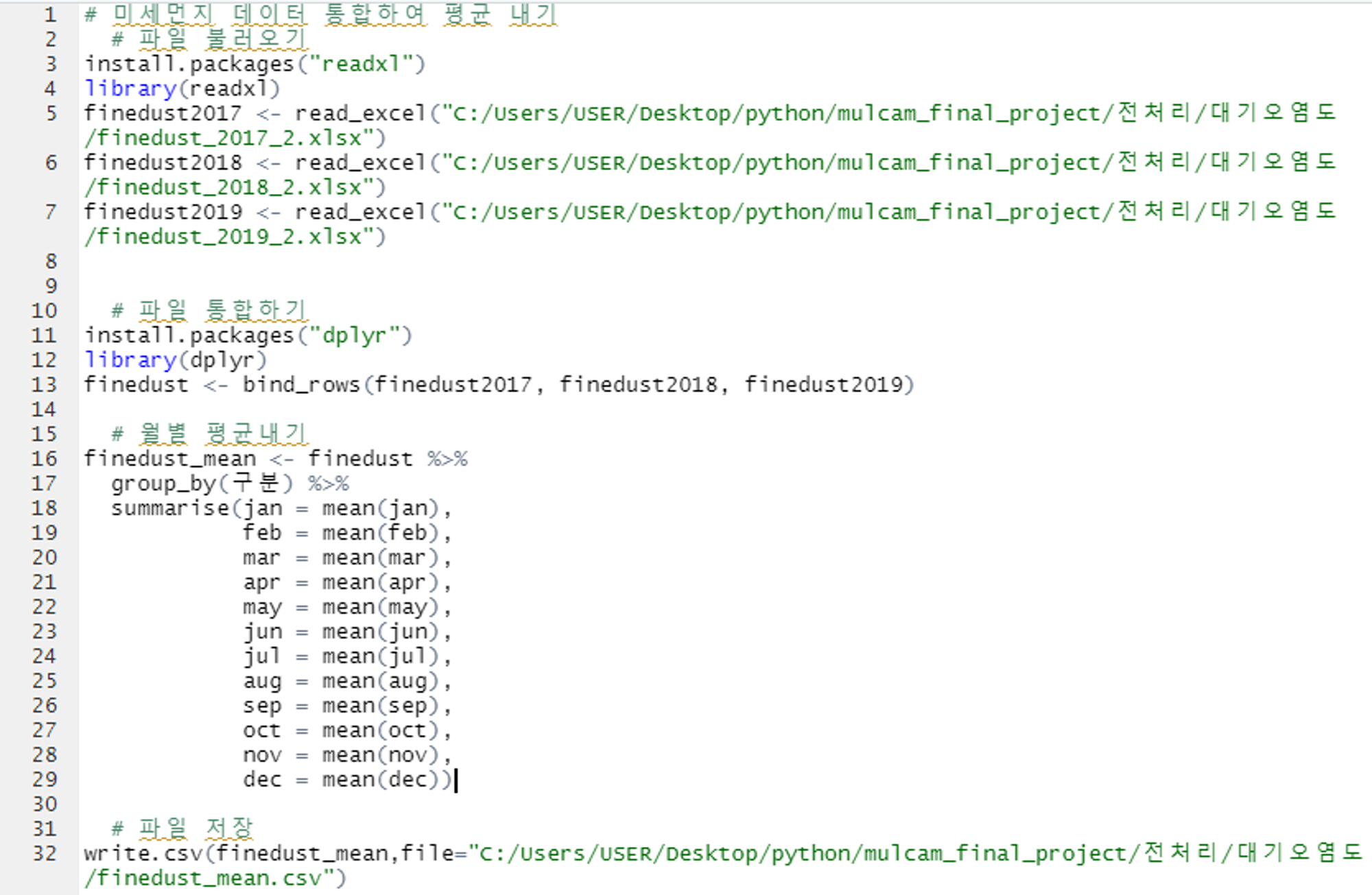
미세먼지 데이터 통합
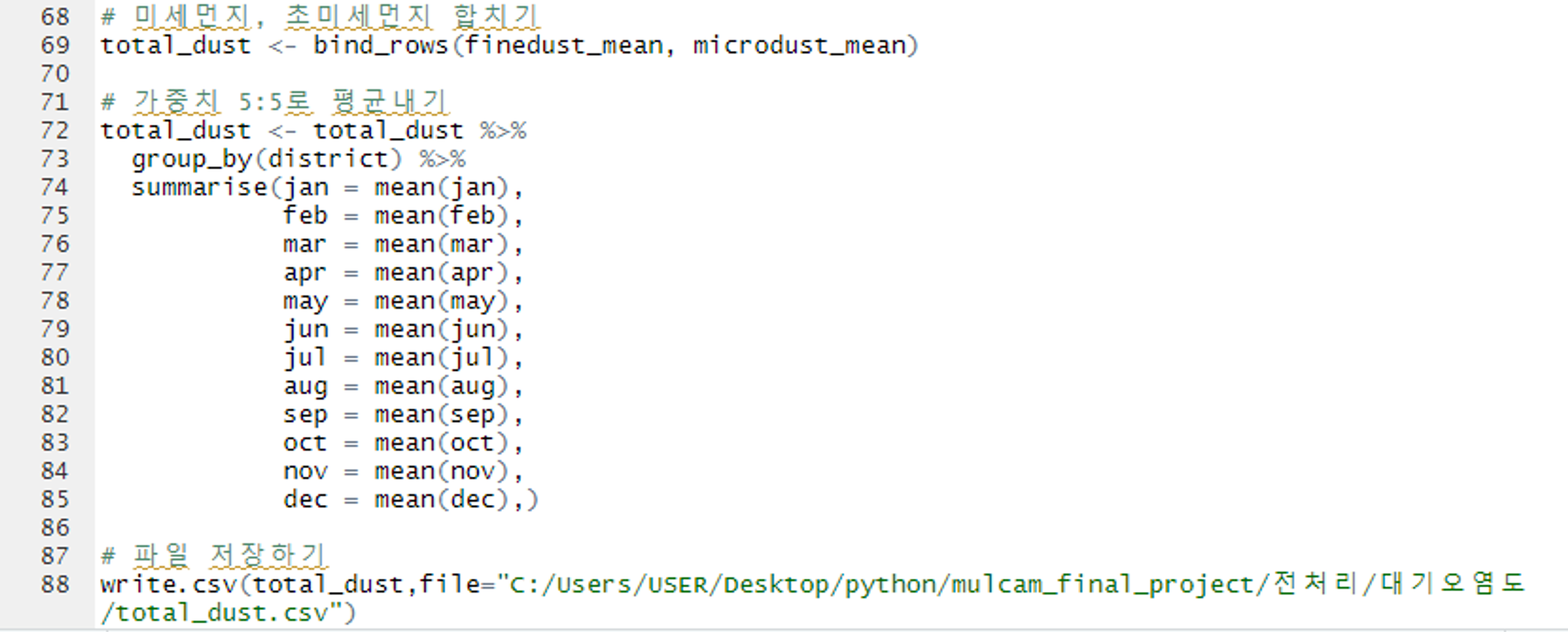
미세먼지 + 초미세먼지
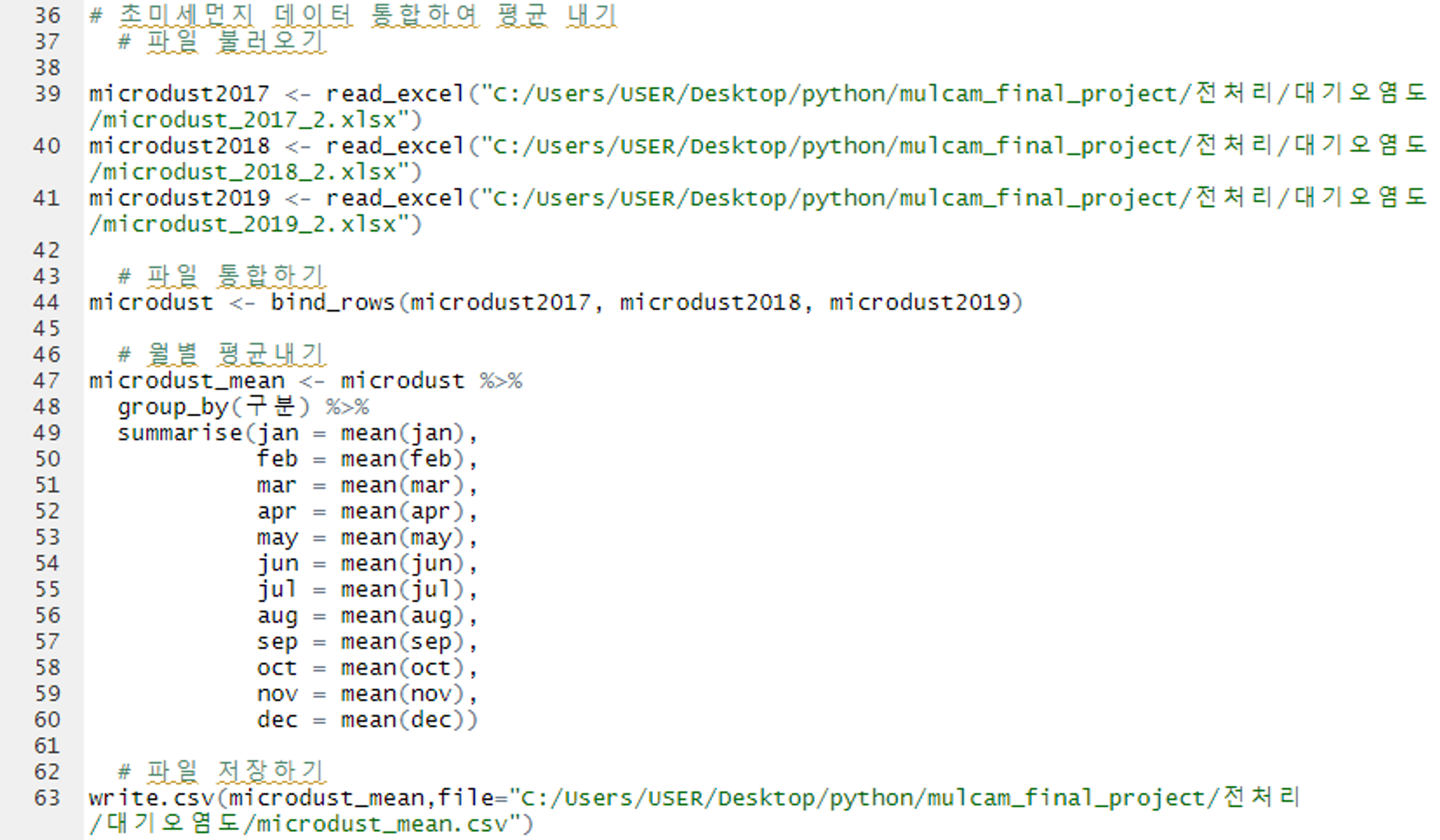
초미세먼지 데이터 통합
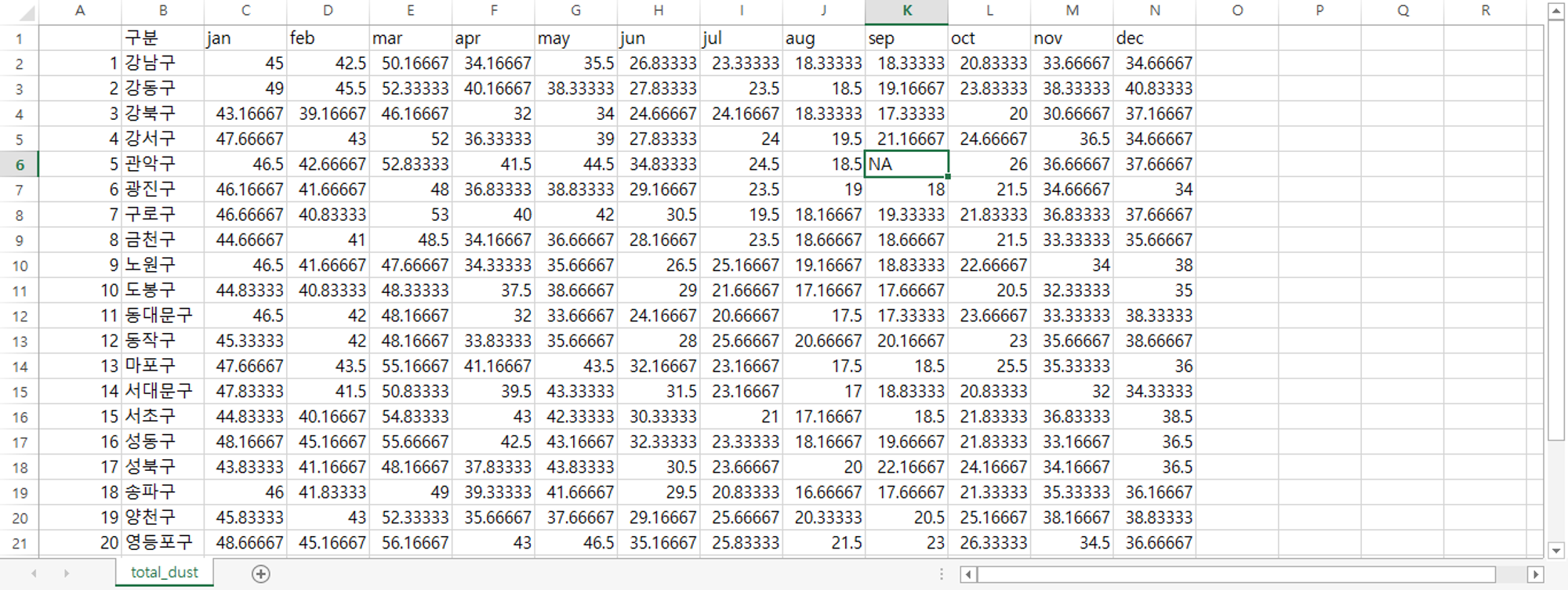
미세먼지 + 초미세먼지 데이터
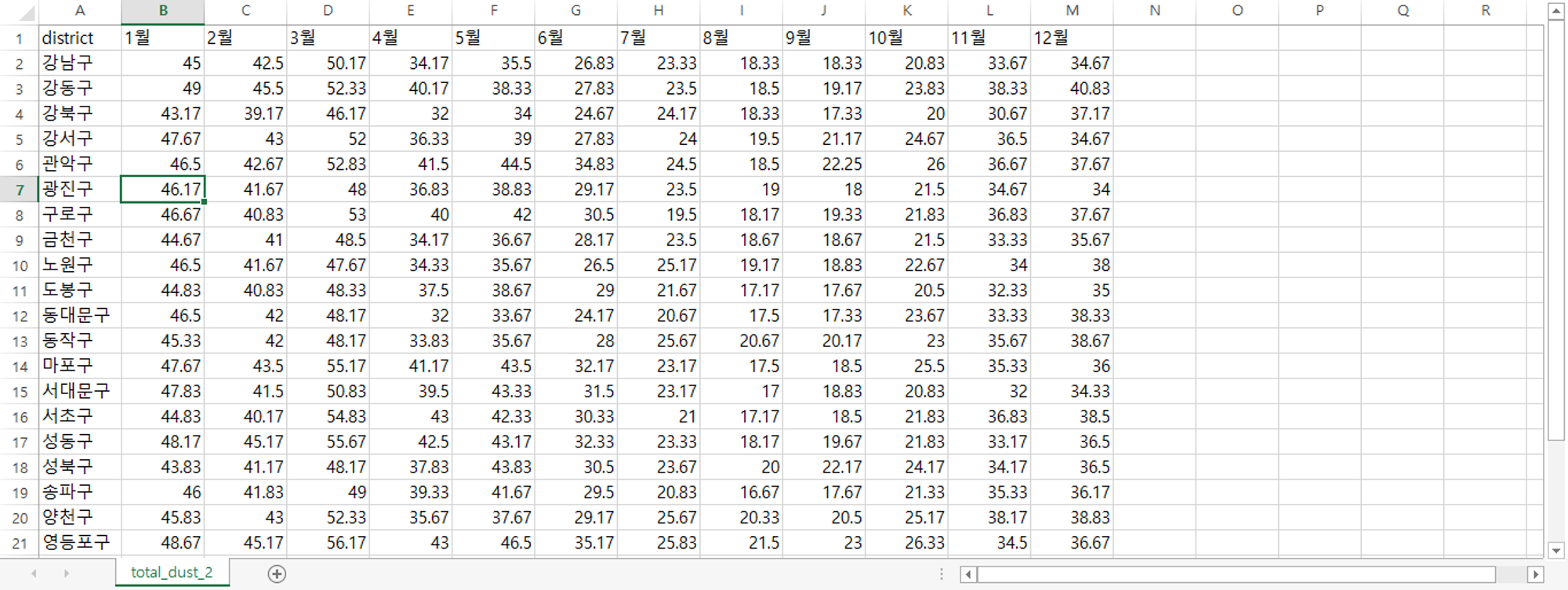
불필요 열 지우고 다시 열 이름 한글로 변경
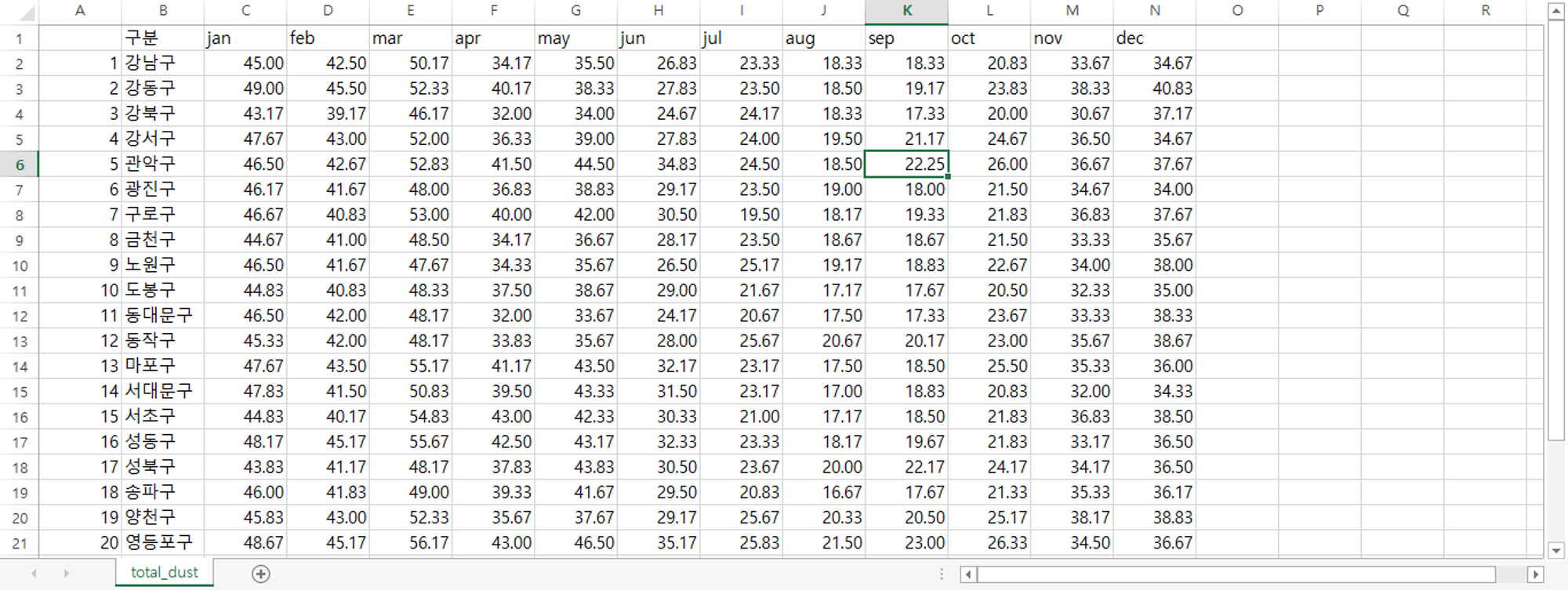
소수점 둘째자리까지, NA 값은 앞뒤 평균으로 대체
4. 유동인구 데이터
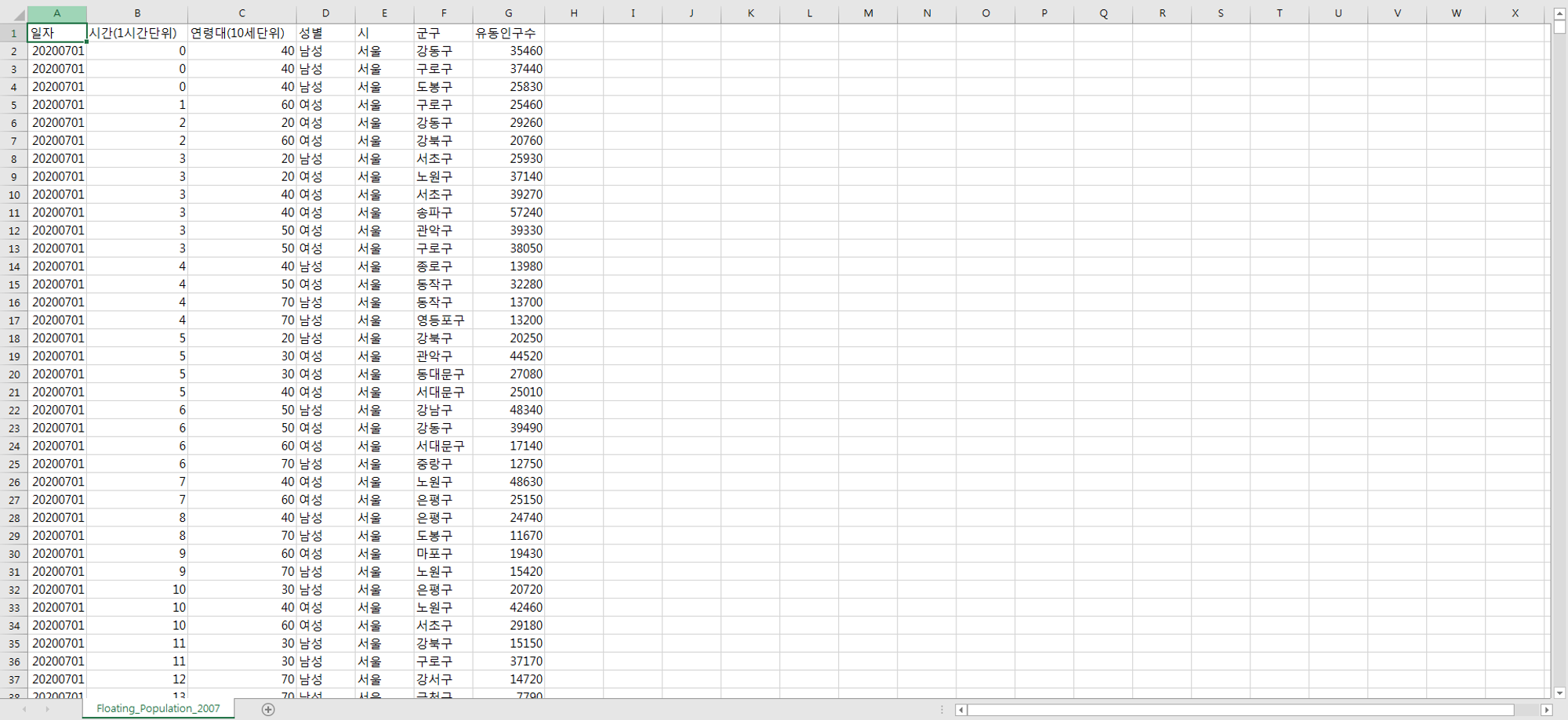
유동인구_raw
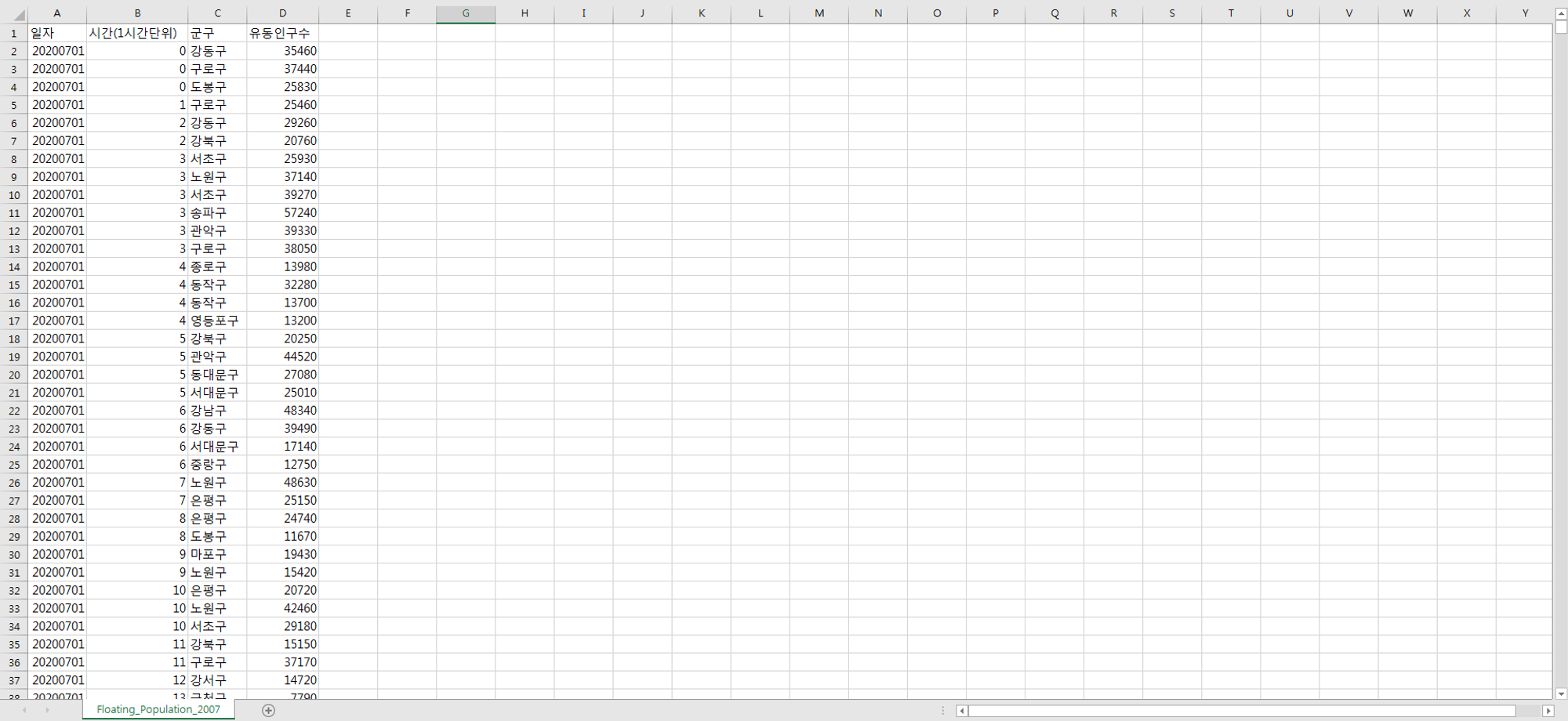
유동인구_불필요행 삭제
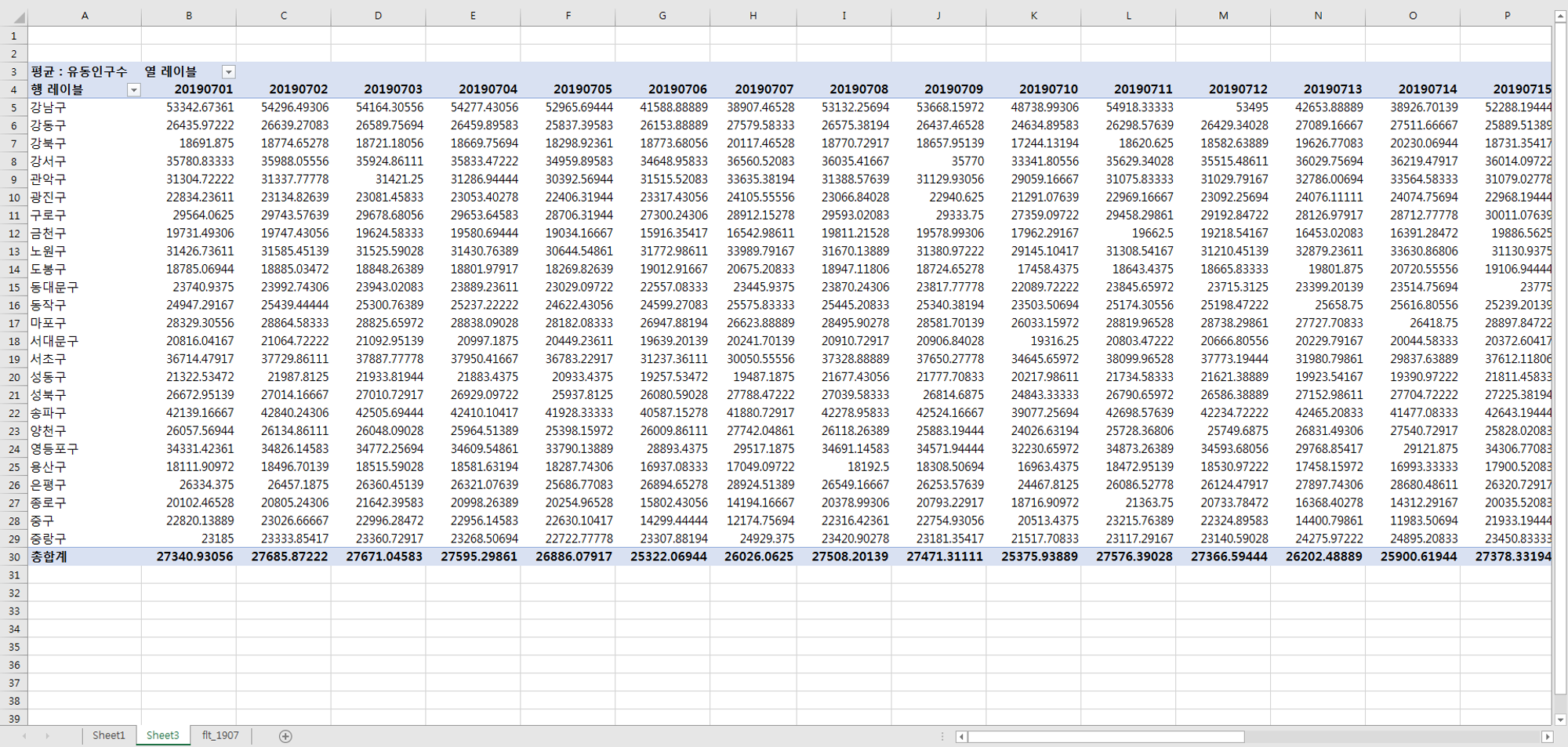
유동인구_피벗테이블 작성
.png&blockId=9e758f0d-0053-44e7-8a09-2006964d5e2c)
유동인구_주말 추출한거 칼럼 명 바꾸고 전처리 완료
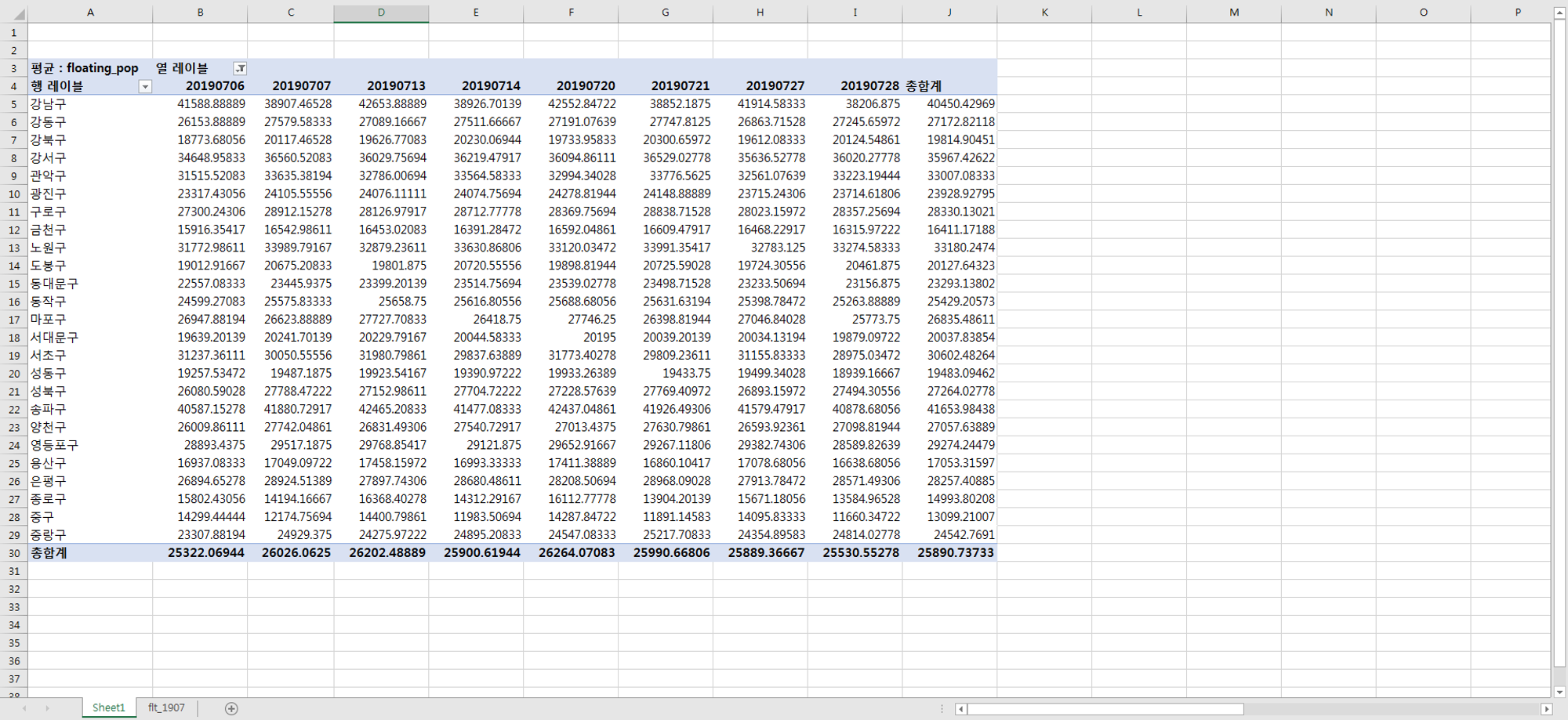
유동인구_주말만 추출
5. 공원 위치 데이터

원본
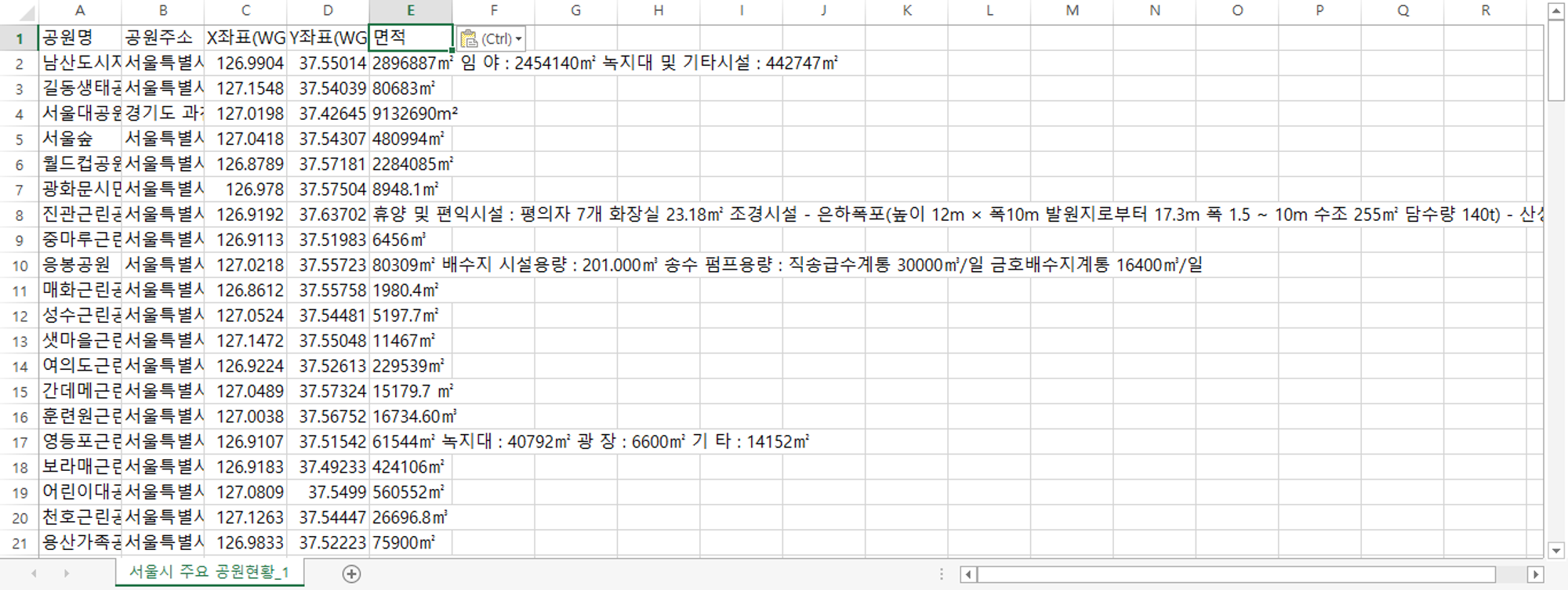
필요항목만 남기고 제거 (공원명, 주소, 위도, 경도, 면적)
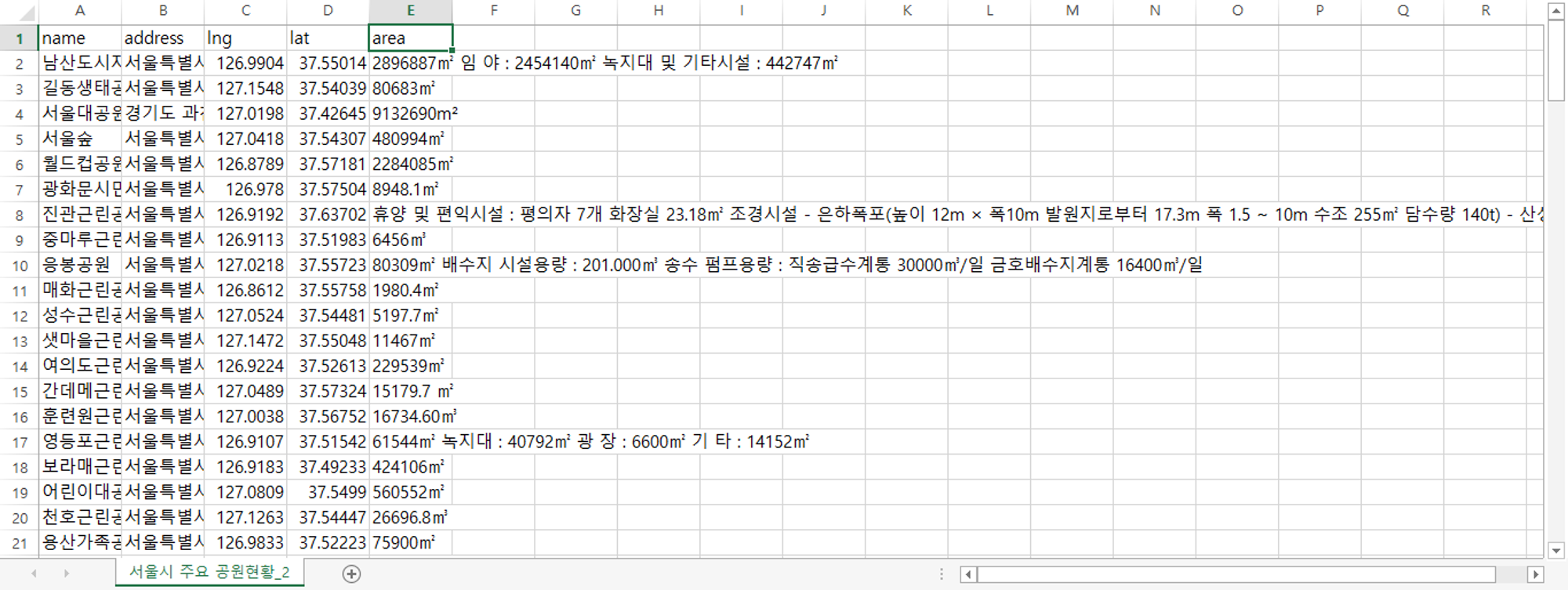
변수명 영어로 변경
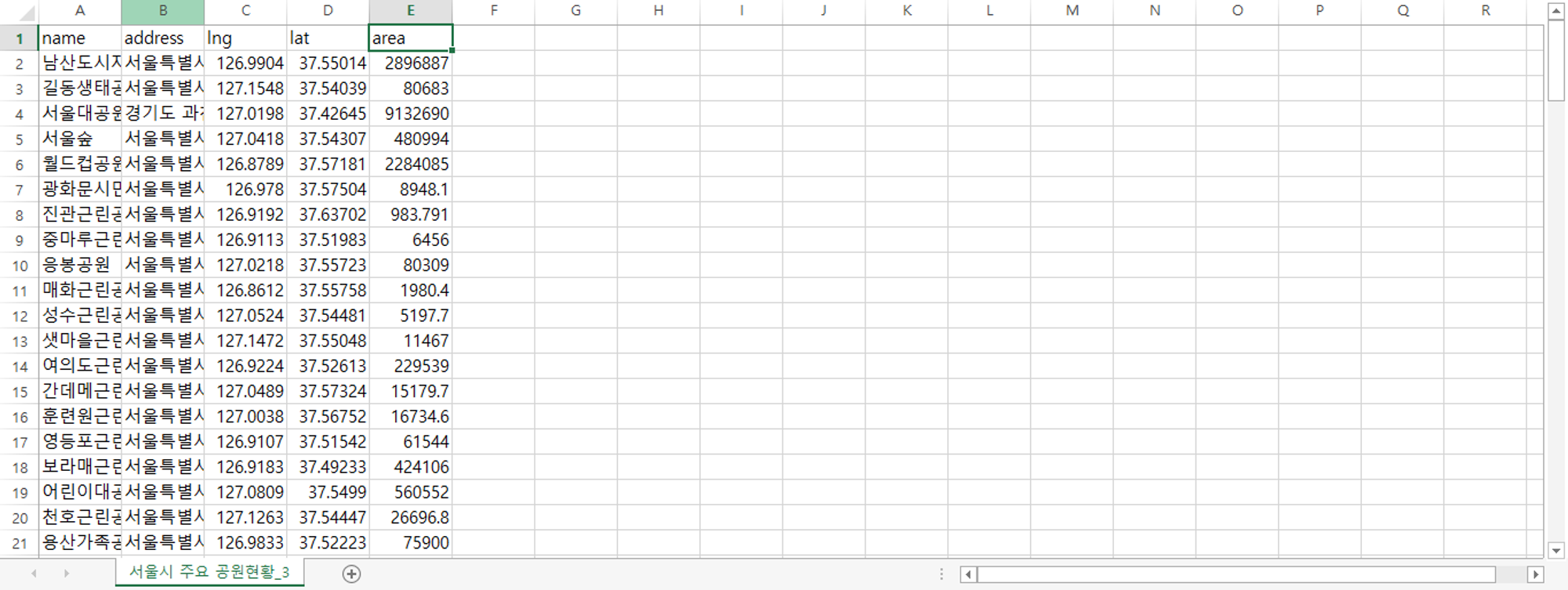
이상치 제거, 단위 제거 후 전처리 완료
6. 맛집 리스트
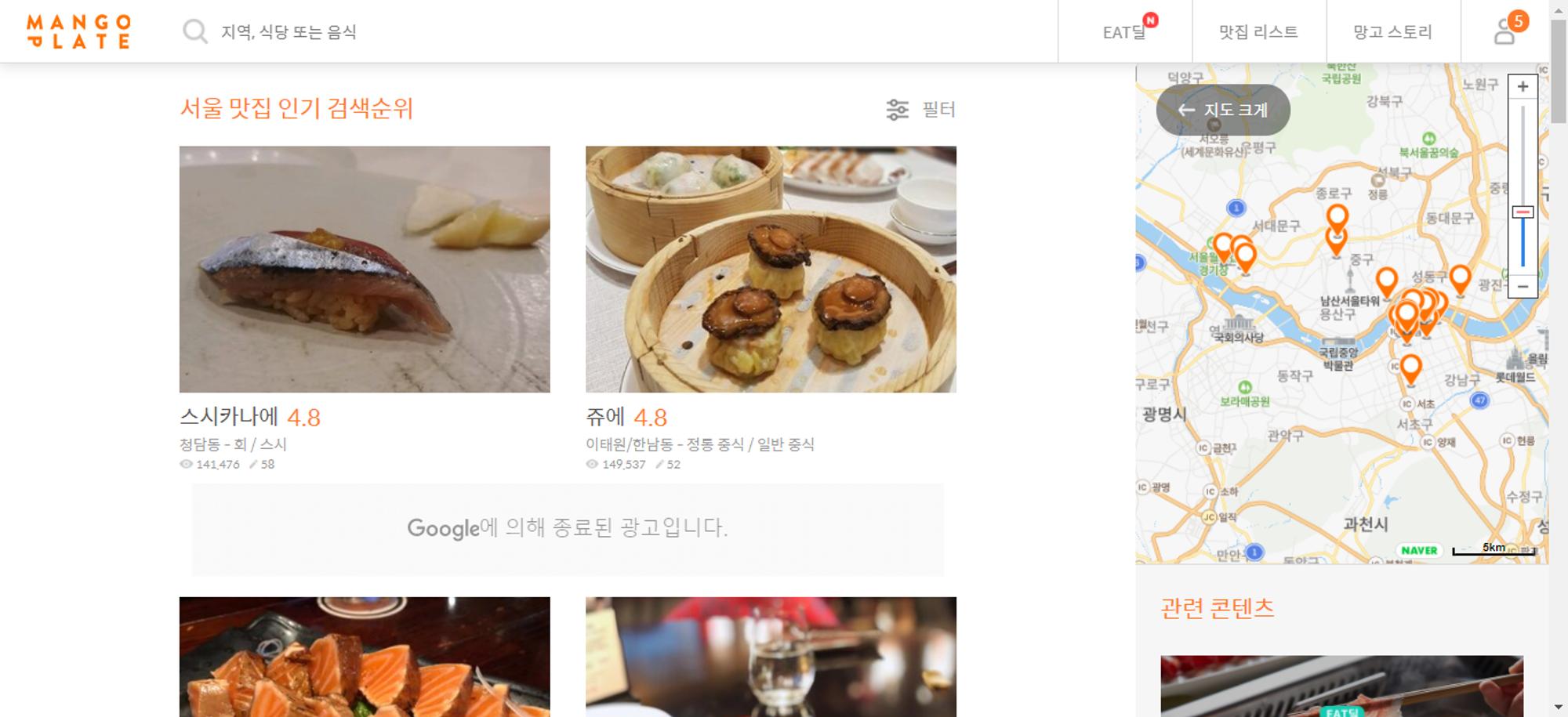
망고 플레이트 검색란에 '서울' 검색 → 총 200개 맛집
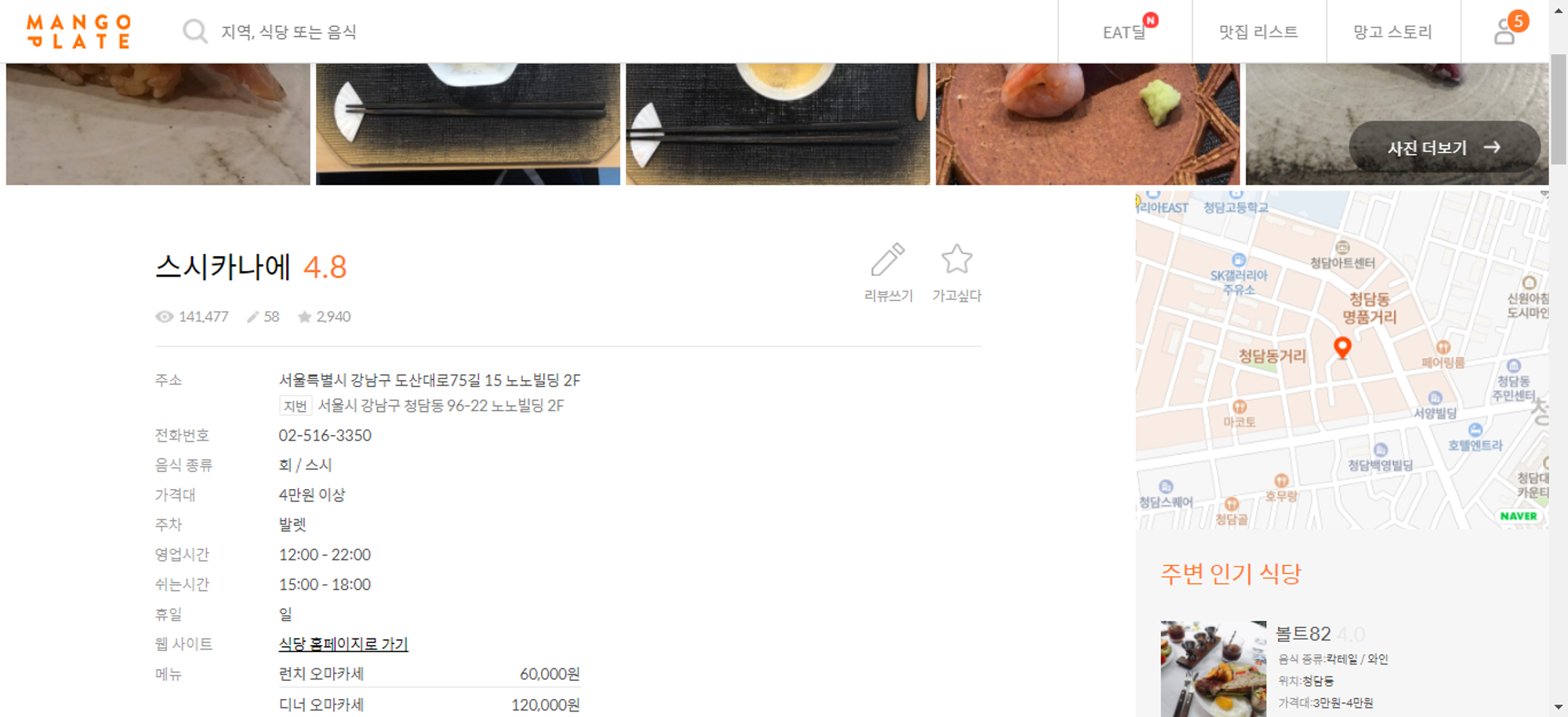
맛집 이름 누르고 들어가면 주소 있음
# =============================================================================
# 망고플레이트 맛집 순위 top 200 크롤
# =============================================================================
## BeautifulSoup 사용하여 html 정보 받아오려했으나 비공개
from bs4 import BeautifulSoup
import requests
url = 'https://www.mangoplate.com/search/%EC%84%9C%EC%9A%B8?keyword=%EC%84%9C%EC%9A%B8&page=1'
html = requests.get(url)
soup = BeautifulSoup(html.text, 'lxml')
soup
soup.find_all('h2', class_= 'title')
## 그러므로 selenium 활용
# 관련 모듈 import
from selenium import webdriver
import time
# 1. 일단 1번째 페이지로 연습
# webdriver로 1번째 페이지 열기
url = 'https://www.mangoplate.com/search/%EC%84%9C%EC%9A%B8?keyword=%EC%84%9C%EC%9A%B8&page=1'
driver = webdriver.Chrome('D:/Temp/chromedriver_win32/chromedriver.exe')
time.sleep(3)
driver.get(url)
# 맛집 가게 정보 있는 class 접근 하여 정보 얻기
title = driver.find_elements_by_class_name('info')
title[0].text
title[1].text
title[2].text
title[19].text
# \n 기준으로 분리 후 맨 앞 요소만 추출하여 맛집 가게 이름 리스트 생성
rest_name = []
for i in range(0, 20) :
rest = title[i].text.split("\n")[0]
rest_name.append(rest)
rest_name
# 2. 위 과정을 1번째 페이지부터 10번째 페이지까지 반복
driver = webdriver.Chrome('D:/Temp/chromedriver_win32/chromedriver.exe')
rest_list = []
for i in range(1, 11) :
url_front = "https://www.mangoplate.com/search/%EC%84%9C%EC%9A%B8?keyword=%EC%84%9C%EC%9A%B8&page="
url = url_front + str(i)
driver.get(url)
time.sleep(3) # 팝업창 닫기 위한 pause....
title = driver.find_elements_by_class_name('info')
for j in range(0, 20) :
rest = title[j].text.split("\n")[0]
rest_list.append(rest)
rest_list
len(rest_list)
# 3. 가게별 주소 정보 얻기
# 첫 번째 가게로 test
url = 'https://www.mangoplate.com/search/%EC%84%9C%EC%9A%B8?keyword=%EC%84%9C%EC%9A%B8&page=1'
driver = webdriver.Chrome('D:/Temp/chromedriver_win32/chromedriver.exe')
time.sleep(3)
driver.get(url)
xpath = '//ul/li[1]/div[1]/figure/figcaption/div/a/h2[@class="title"]'
driver.find_element_by_xpath(xpath).click()
address = driver.find_element_by_class_name("only-desktop").text
address
# url 주소들의 xpath 분석 해보니 테이블 순서대로 태그가 달라짐...
'''
/ul/li[1]/div[1]/figure/figcaption/div/a
/ul/li[1]/div[2]/figure/figcaption/div/a
/ul/li[2]/div[1]/figure/figcaption/div/a
/ul/li[2]/div[2]/figure/figcaption/div/a
'''
# 4. 맛집 가게 이름과 주소 전체 데이터 얻기
from tqdm import tqdm
driver = webdriver.Chrome('D:/Temp/chromedriver_win32/chromedriver.exe')
rest_list = []
address_list = []
for i in tqdm(range(1, 11)) :
url_front = "https://www.mangoplate.com/search/%EC%84%9C%EC%9A%B8?keyword=%EC%84%9C%EC%9A%B8&page="
url = url_front + str(i)
driver.get(url)
time.sleep(3) # 팝업창 닫기 위한 pause
for j in range(1, 11) :
# 가게 주소 정보 얻기
for m in range(1,3) :
xpath = '//li[' + str(j) + ']/div[' + str(m) + ']/figure/figcaption/div/a/h2[@class="title"]'
driver.find_element_by_xpath(xpath).click()
time.sleep(1)
address = driver.find_element_by_class_name("only-desktop").text
address = address.split("\n")[0][3:]
address_list.append(address)
driver.back()
time.sleep(1)
# 가게 이름 얻기
title = driver.find_elements_by_class_name('info')
for n in range(0, 20) :
rest = title[n].text.split(" ")[0]
rest_list.append(rest)
time.sleep(1)
rest_list
len(rest_list)
address_list
len(address_list)
# 5. 데이터프레임으로 변환 후 csv로 저장
from pandas import DataFrame
data = {'restaurant' : rest_list,
'address' : address_list}
df = DataFrame(data, columns=['restaurant', 'address'])
df.to_csv('C:/Users/USER/Desktop/python/mulcam_final_project/restaurant.csv',encoding='euc-kr')
Python
복사