
논문 : 개인 성향 추출을 위한 딥러닝 기반 SNS 리뷰 분석 방법에 관한 연구
논문 정보 : 키워드 1. 서론
기존의 해시태그 활용 분석 연구 :
1.
딥러닝을 이용한 SNS 분석기반 개인 관심사 추출 방법
•
문제점 : 여러 관심사에 대한 다양한 의견을 추출하기보다는 의견 중 가장 높은 가중치를 갖는 의견만을 추출한다.
2.
딥러닝 기반 비정상 배달음식 리뷰 이미지 감지 시스템
•
문제점 : 리뷰에 대한 이미지만을 분석 대상으로 선정함으로써 관련 텍스트 데이터에 대한 분석 내용을 반영하지 못한다.
3.
텍스트 마이닝 기법을 활용한 편의점 이용 고객의 트위터 리뷰에 대한 감성 분석
•
문제점 : 편의점을 대상으로 이용 고객의 만족도에 따른 긍정/부정에 대한 결과값만을 도출함으로 개인적 성향에 따른 세분화된 의견 수렴이 어렵다.
⇒ 이러한 문제점을 해결하는 것이 이 연구의 목적이다.
방법
1.
객체 인식을 이용하여 약 42,300개의 음식 이미지 데이터 및 종류를 카테고라이징(categorizing)하여 모델을 설정한다
2.
감성분석을 이용하여 109,734개의 리뷰 데이터를 학습한다.
3.
집합 알고리즘을 통해 성향을 추출한다.
2. 관련 연구
2.1 Opinion Mining (감성분석)
기존 감성분석의 한계 :
•
대상 문서에 포함된 감성을 긍정/부정 혹은 긍/부정의 비율로만 나타내므로 그 결과가 단조롭다.
•
또한 SNS 분석에 광범위하게 사용 가능한 감성사전이 제한적이거나 영문 위주로 만들어진 것들이 대부분이다.
따라서, 본 논문에서는 감성사전을 따로 구축하지 않고 단어의 빈도를 활용하여 다양한 감성 정도를 수치화하여 적용한 감성분석 모델을 제안한다.
2.2 객체 인식 연구
객체 인식 연구 모델의 발전 :
합성곱 신경망(CNN: Convolutional Neural Network)
R-CNN(Region-based CNN)
Fast-R-CNN
Faster R-CNN
YOLO(You Only Look Once)
YOLOv2
YOLOv3
본 논문에서는 객체 인식 기술인 YOLOv3 모델을 이용하여 음식 이미지에 대한 분류 모델을 제안하였다.
3. SNS 리뷰 분석 시스템 설계 및 구현
3.1 시스템 구성도
본 논문에서 개발한 SNS 리뷰 분석을 위한 개인적 성향 추출 방법의 전체적인 구조는 오른쪽과 같다.
1.
딥러닝 모델 구축을 위해 이미지 및 텍스트 데이터를 수집 후 정제과정을 통해 관련 없는 데이터를 삭제한다.
2.
이미지 데이터의 개수의 제약 문제는 이미지를 증식하여 해결한다.
3.
각 데이터를 이용하여 감성분석 및 객체 인식 모델을 학습한다.
4.
입력된 리뷰 데이터는 구축된 모델을 통해 카테고리가 분류된다.
5.
각각의 카테고리는 집합 알고리즘을 거쳐 사용자의 개인적 성향을 추출한다.
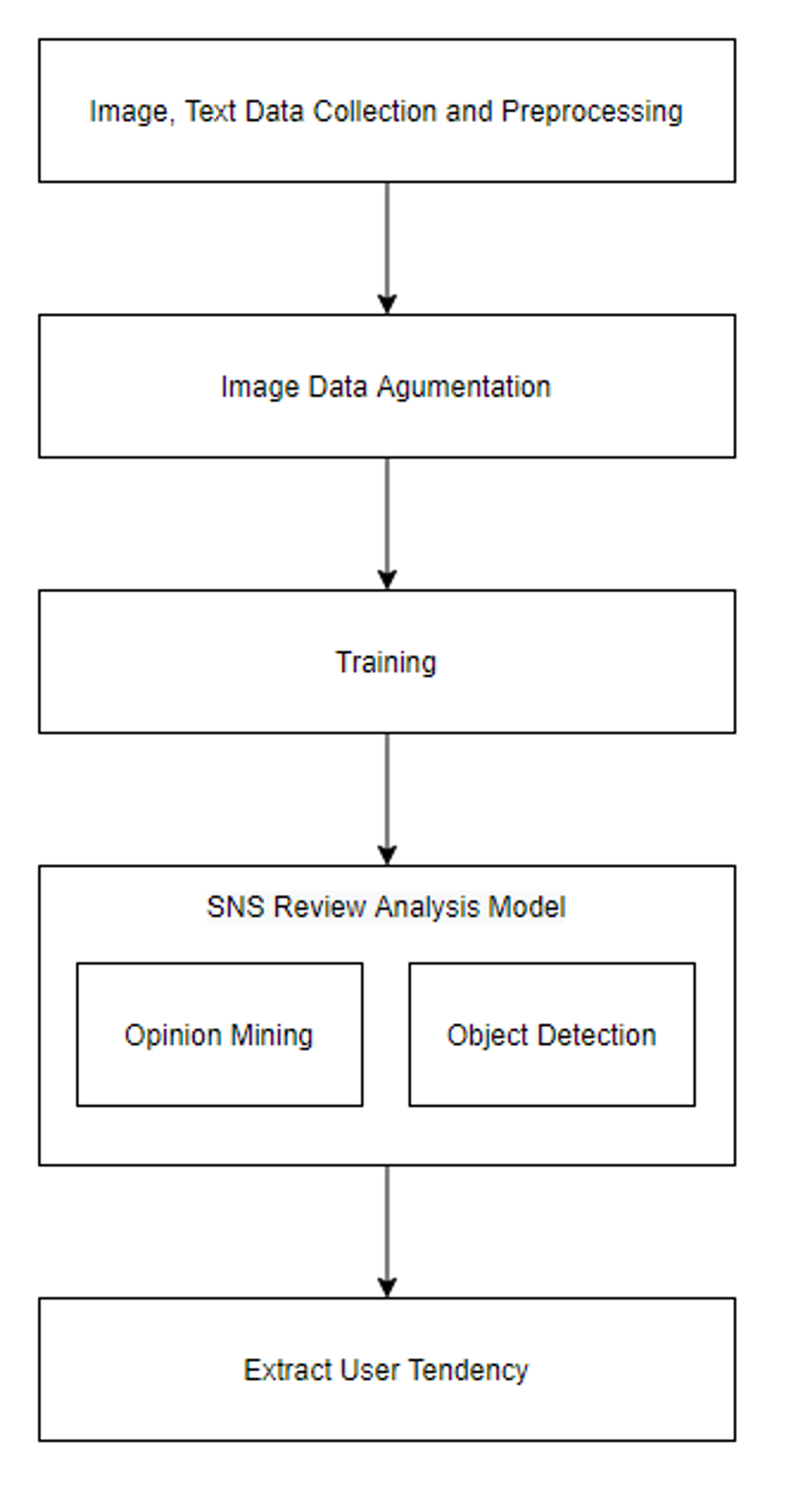
Fig. 3. Structure of proposed system
3.2 데이터 수집 및 정제
3.2.1. 객체인식 모델 구축을 위한 이미지 데이터 수집
•
Python의 BeautifulSoup, Selenium 라이브러리, 네이버 검색 API, Bing Image Search API를 이용
•
일반적으로 사람들이 쉽게 접할 수 있는 42개의 음식 종류에 해당하는 이미지를 총 10만 건 크롤링하였다.
수집한 이미지 중 정확한 음식 이미지만을 분류하여 총 12,967개의 이미지 데이터를 수집하였다.
3.2.2 감성분석 모델 구축을 위한 텍스트 데이터 수집
•
네이버 검색 API를 이용
•
음식에 대한 표현과 장소에 대한 분위기 등을 범주에 두어 14개의 카테고리로 나누었다.
•
정의한 14개의 텍스트 카테고리에 해당하는 블로그 음식점 리뷰 총 13만 건을 수집하였다.
•
수집한 데이터 중 내용이 중복되거나 빈 공백으로 채워져 있는 것, 한글 외의 부호를 제거한 후 정제하여 총 121,927건의 음식점 리뷰를 추출하였다.

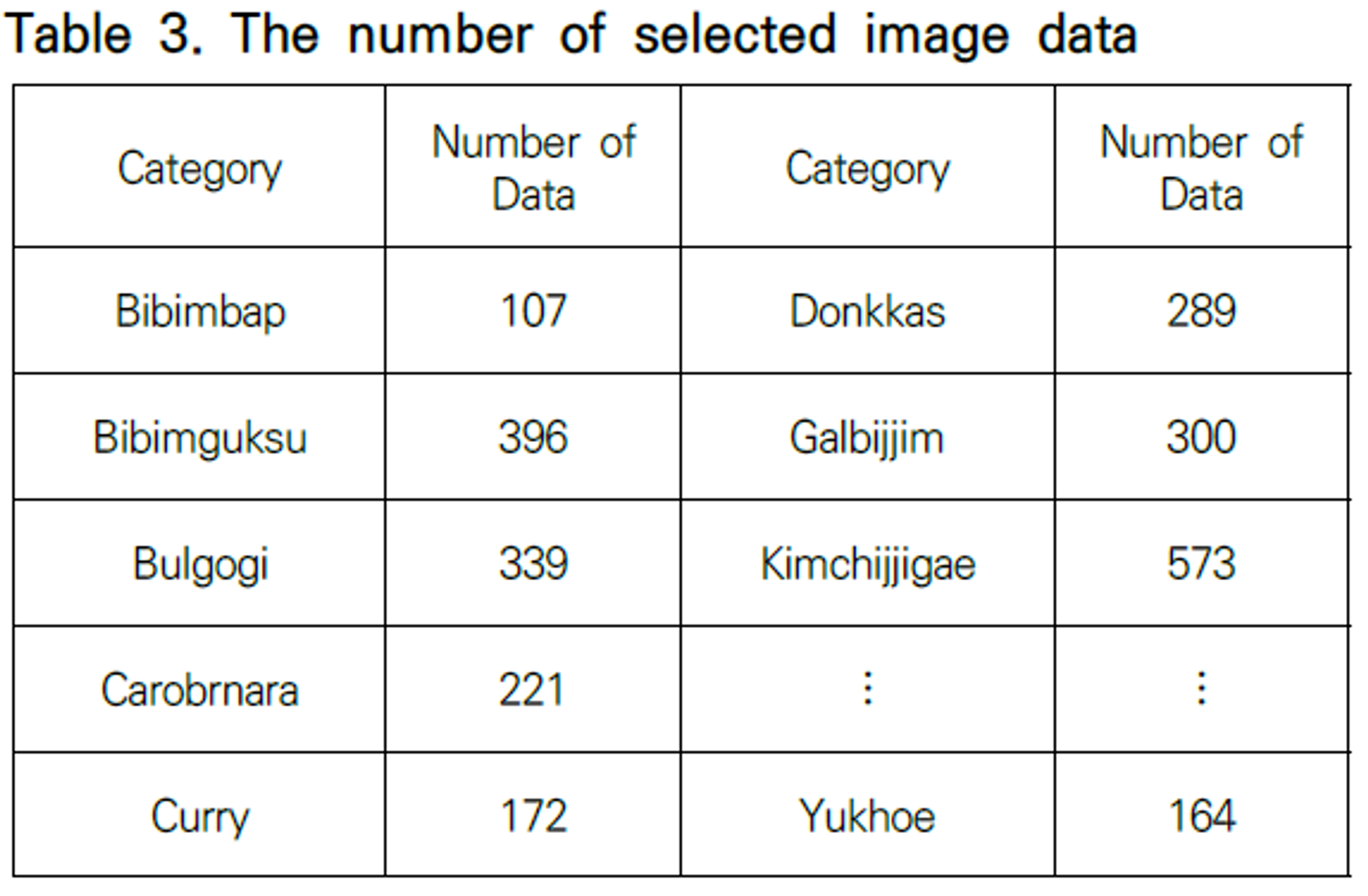
3.3 데이터 증식
이미지 데이터의 경우 오른쪽 Table 3과 같이 음식 종류에 따라서 준비할 수 있는 개수가 많게는 573개로부터 적게는 107개의 이미지로 개수의 편차가 크다.
데이터 증식(Data Augmentation) 기법
•
학습이미지 개수의 제약문제를 해결 할 수 있는 방법
•
본 논문에서는 Zoom(원본 이미지 확대, 축소), Flip(원본 이미지 좌우 대칭, 상하 대칭), Rotation(원본 이미지 기울이기), Shift(원본 이미지 상하좌우로 이동)를 음식 이미지에 무작위로 적용하여 학습 이미지의 개수를 늘렸다.
•
즉, 42개의 음식 카테고리 각각의 이미지 개수를 1100개로 추가 생성하여 총 47,000개의 이미지로 데이터 증식을 하였으며 해당 데이터 모두 Annotation 작업을 적용하였다.
3.4 SNS 리뷰 분석 모델
본 논문에서 제시한 SNS 리뷰 분석 모델은 객체 인식 모델 YOLOv3 + 감성분석 모델 BiLSTM 로 구성되어 있다.
3.4.1 객체 인식 모델 YOLOv3
•
Darknet-53 아키텍처 사용, 총 53개의 층으로 이루어져 있다.
•
YOLOv3에서는 Darknet-53의 아키텍처 두 개를 이용하여 총 106개의 Layer를 활용하여 학습하게 된다.
•
본 논문에서 학습을 진행한 클래스는 총 42개, 마지막 컨볼루션 레이어의 필터 수는 141개다.
•
Batch size = 64, Learning rate = 0.001, Max epoch size = 200,000, Classes = 4
•
미리 학습된 가중치 모델로 Darknet-53을 사용하여 추가 학습을 진행하였다.
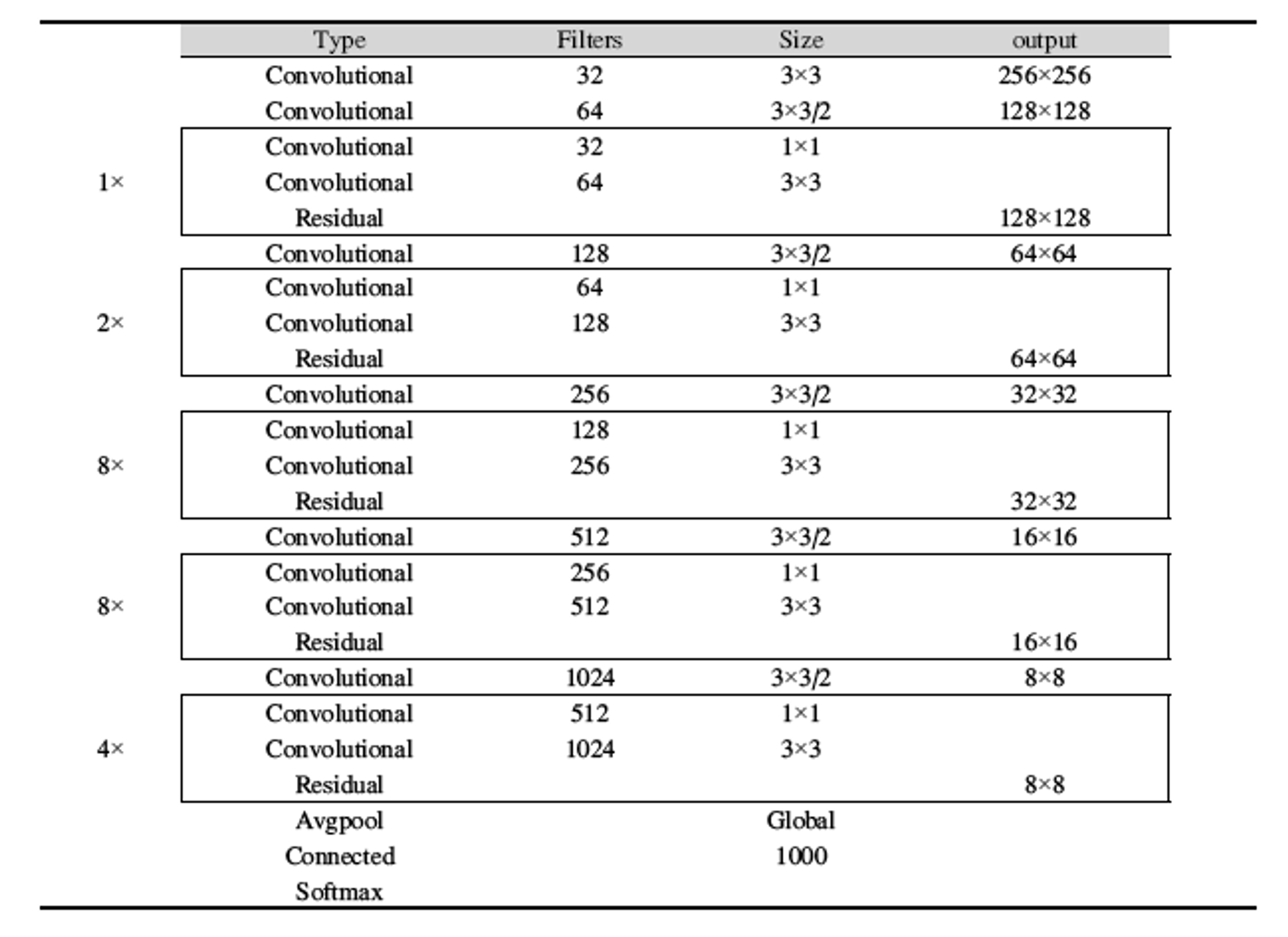
Fig. 4. Darknet-53 architecture
3.4.2 감성분석 모델 BiLSTM
•
전처리된 텍스트는 한국어 정보 처리를 위한 패키지인 Konlpy의 Twitter 라이브러리를 사용하여 수집된 데이터를 단어로 분리하고 품사를 태깅한다.
•
리뷰가 너무 짧은 경우 명확한 분류가 어렵기 때문에 형태소 분석 후 토큰이 5개 이상인 리뷰만 분석 대상으로 사용하였다.
•
리뷰로부터 형태소가 태깅된 단어들을 추출하고 추출된 단어들을 Word2Vec의 Skip-gram 방식을 통해 벡터들로 임베딩한다. (window = 5)
임베딩 과정에서 정확도를 높이기 위해 출현 빈도가 10번 미만인 단어는 분석에서 제외하였으며, 임베딩 벡터의 크기는 300으로 진행하였다.
•
벡터화된 데이터는 128개의 뉴런으로 생성된 양방
향 LSTM 층을 지나게 된다.
LSTM의 설정은 분류 문제에서 모델 성능의 향상을 위해 입력 게이트는 forward로, 출력 게이트는 backward로 설정하였으며 이를 양방향으로 설정한 이유는 더 빠른 속도로 완전한 학습을 하기 위함이다.
•
LSTM 이후에는 Fully Connected Layer를 거치게 하여 특정 학습용 데이터에 학습이 치우치는현상을 막는다.
•
그 후 Softmax 함수를 적용해 출력값의 총합이 1이 되도록 정규화한 뒤 분류한다.
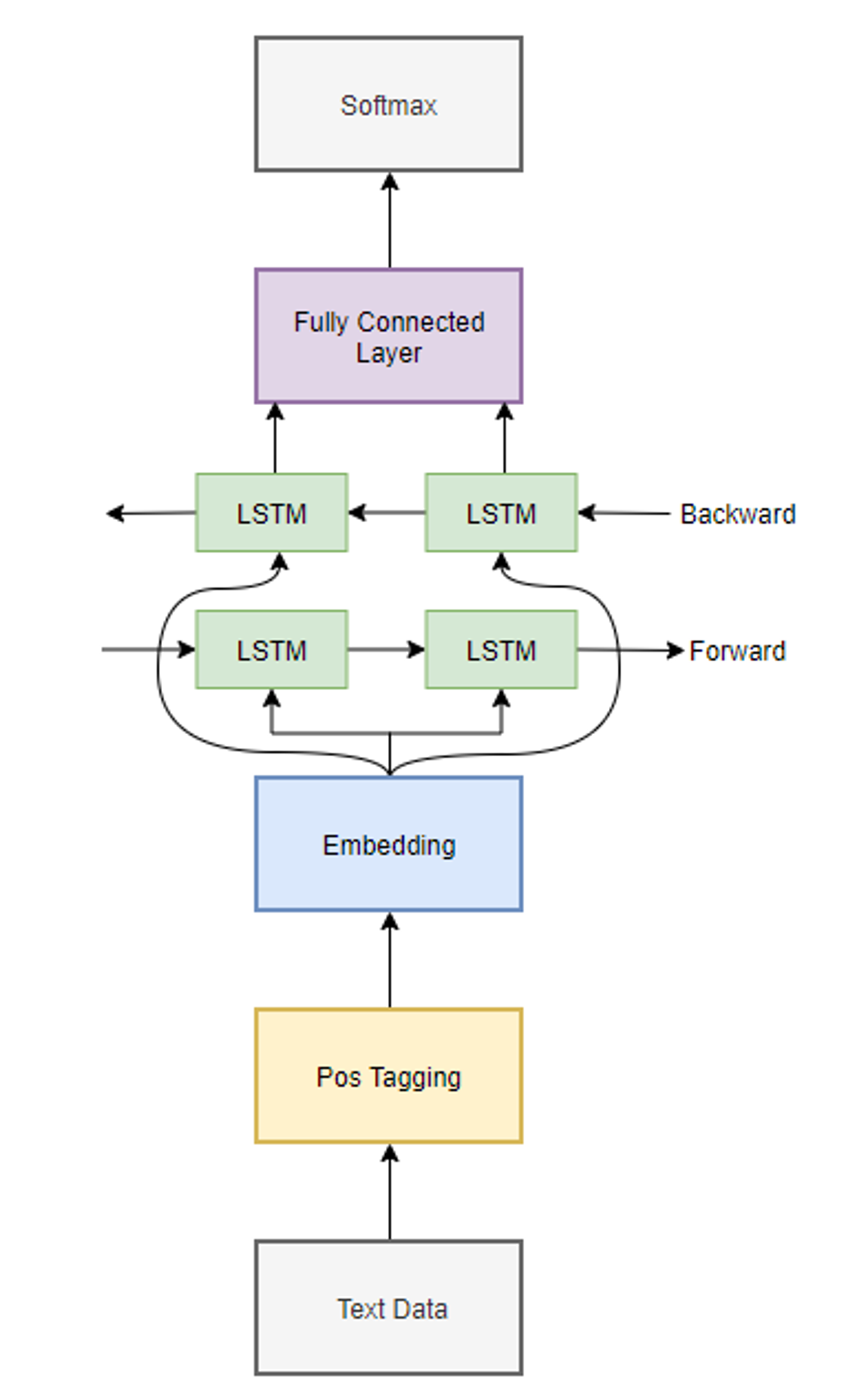
Fig. 5. Structure of opinion mining model
3.5 개인적 성향 추출
본 논문에서는 YOLOv3 모델과 BiLSTM 모델을 이용하여 SNS 리뷰 카테고리 추출 후 집합 알고리즘을 통해 사용자의 성향을 추출한다. 해당 과정은 다음과 같다.
1. 구축된 모델을 통한 입력값 설정
•
원소 A : 분류된 상위 첫 번째 이미지 카테고리를 저장
•
배열 B : 분류된 상위 3개의 텍스트 카테고리를 저장
2. 배열 B의 모든 부분 집합을 순환할 때까지 아래 과정을 반복한다.
•
여러 성향을 조합하기 위해 배열 B의 부분집합을 C에 저장한다.
•
텍스트 뿐만 아니라 이미지에 대한 성향을 반영하기 위해 A와 C를 합친 하나의 문자열을 결과 배열에 저장한다.
3. 결과 배열을 반환하여 사용자의 다양한 개인적 성향을 추출한다.

Fig. 6. Pseudo-code of the algorithm
4. 실험 및 결과
4.1 실험 데이터
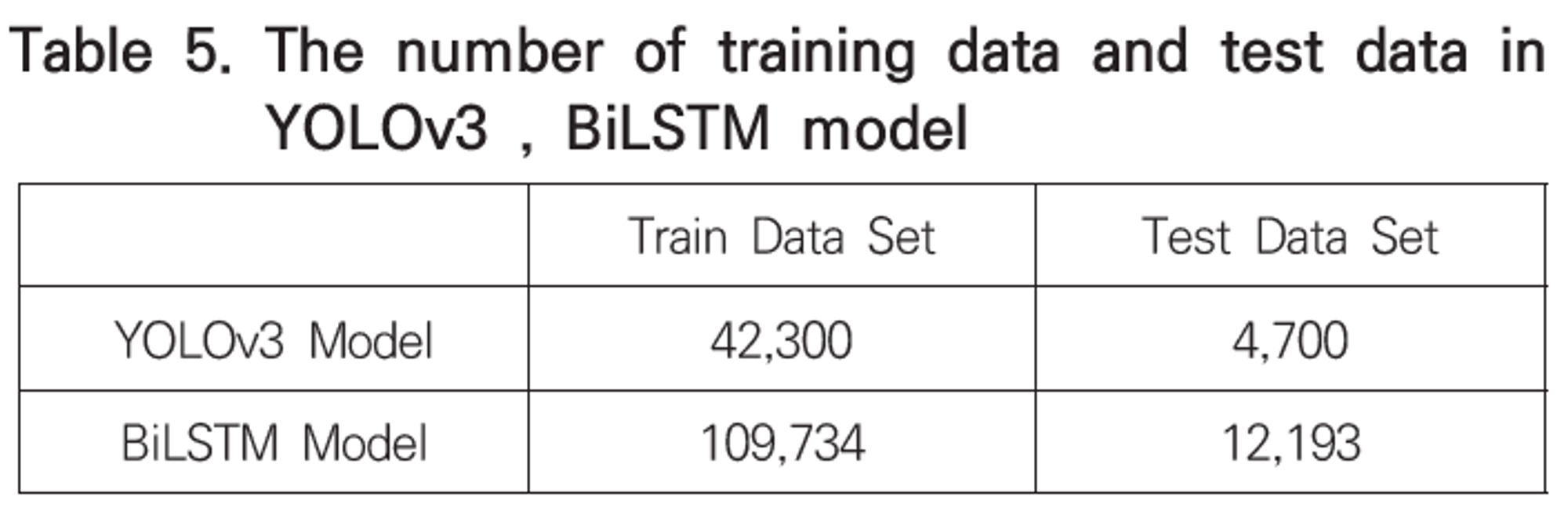
4.2 실험 결과
4.2.1 Top-N 정확률
YOLOv3 모델 평가를 위해 이미지 분류 모델 평가에 사용되는 Top-N 정확률을 이용한다.
Top-N 정확률 실험이란?
결과 : 가장 높은 성능을 보여주는 100,000 Epoch의 모델을 최종 모델로 선정하였다.
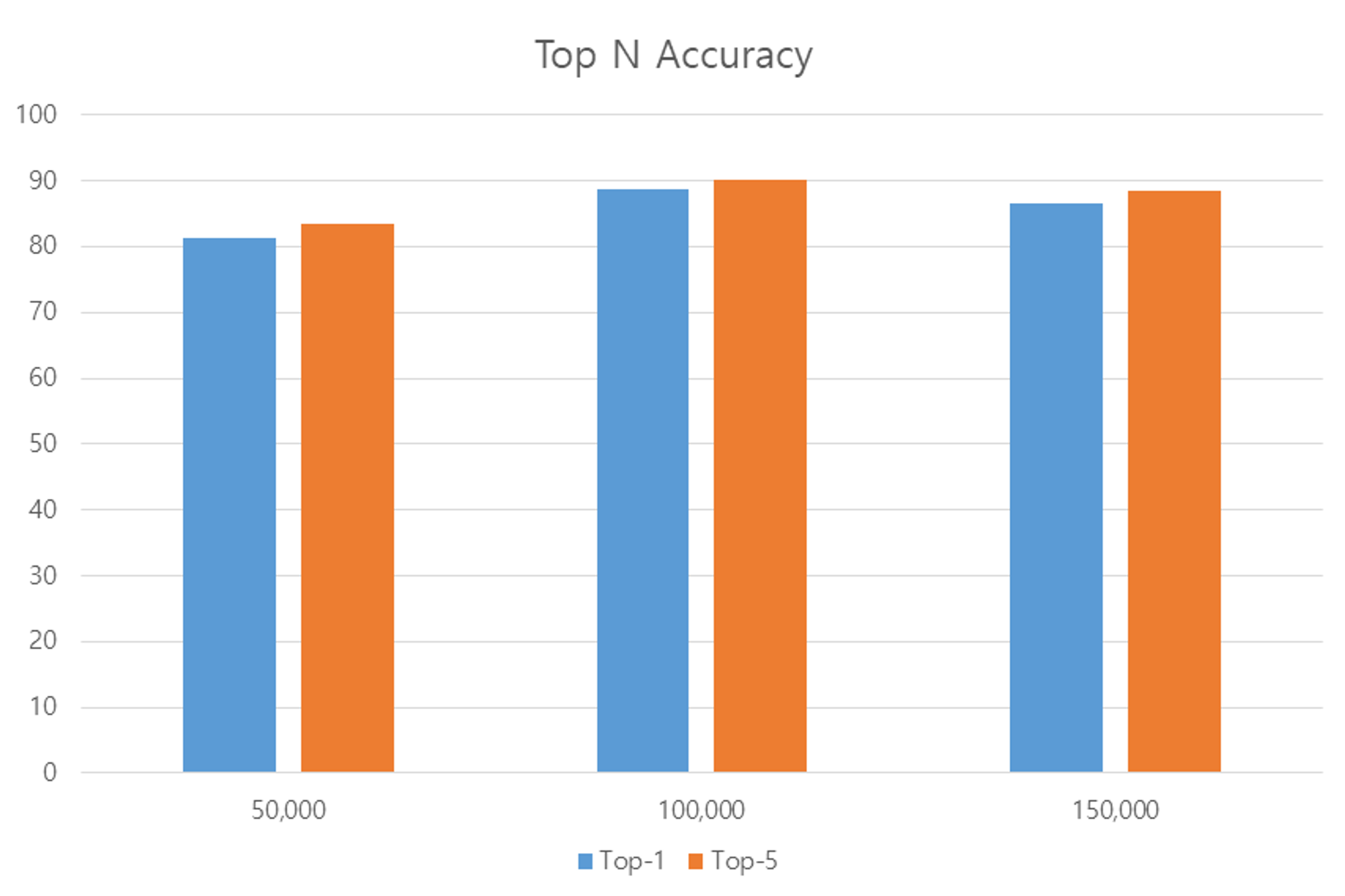
Fig. 7. Epoch 별 구축된 YOLO 모델에 테스트 데이터를 사용하여 측정한 평가 결과
4.2.2 분류 성능 평가 지표
BiLSTM 모델의 평가를 위해 분류 성능 평가 지표라고 불리는 Precision(정밀도), Recall(재현율), Accuracy(정확도), F-measure를 사용한다.
•
TP(True Positive) : 텍스트 카테고리의 정답을 정확하게 예측한 경우
•
TN(True Nagtive) : 카테고리의 오분류를 정확하게 예측한 경우
•
FP(False Positive) : 카테고리를 오분류 한 경우
•
FN(False Negative) : 오분류된 카테고리를 정답이라고 예측한 경우

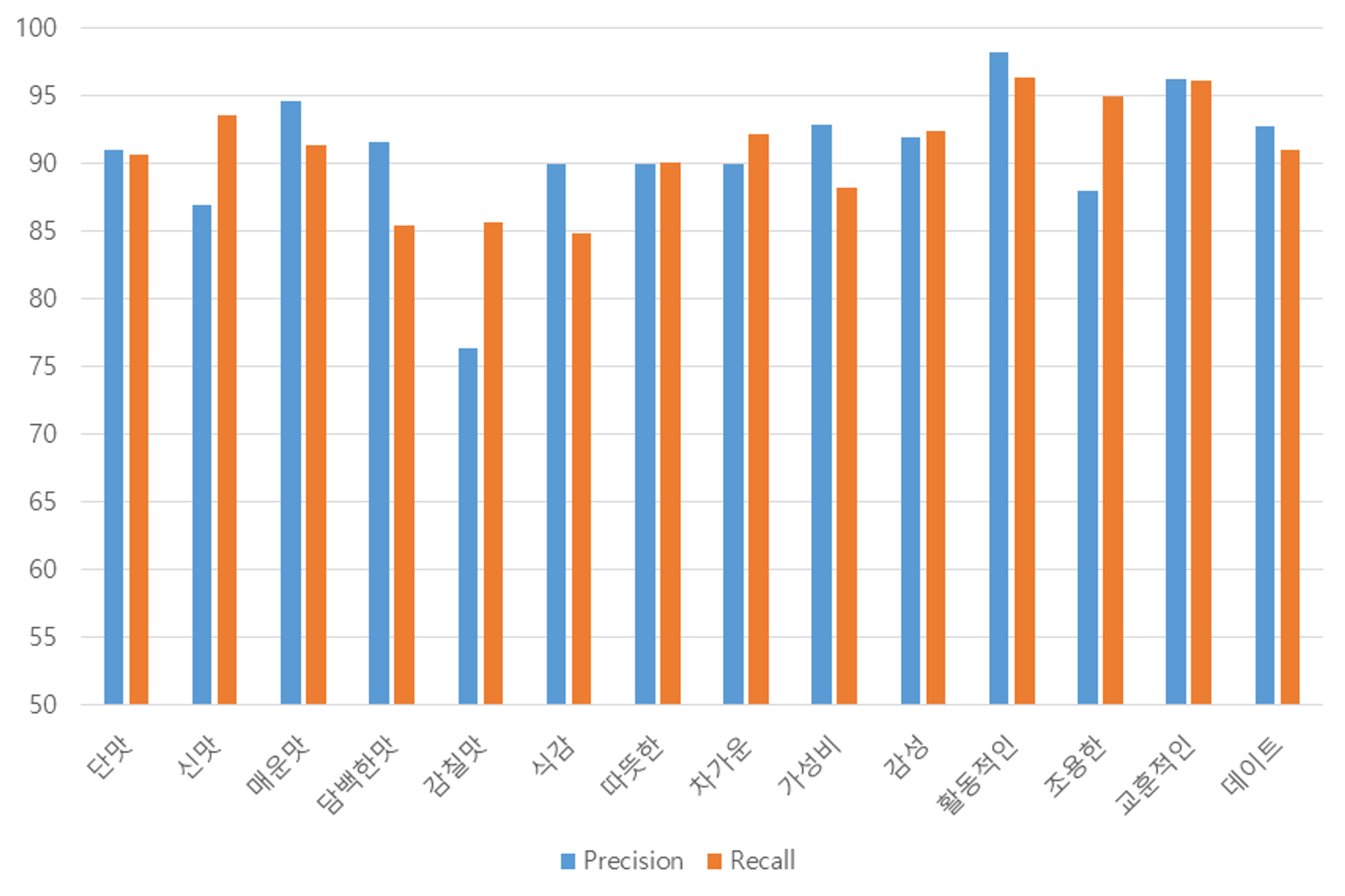
Fig 8. 카테고리 별 정밀도 및 재현율
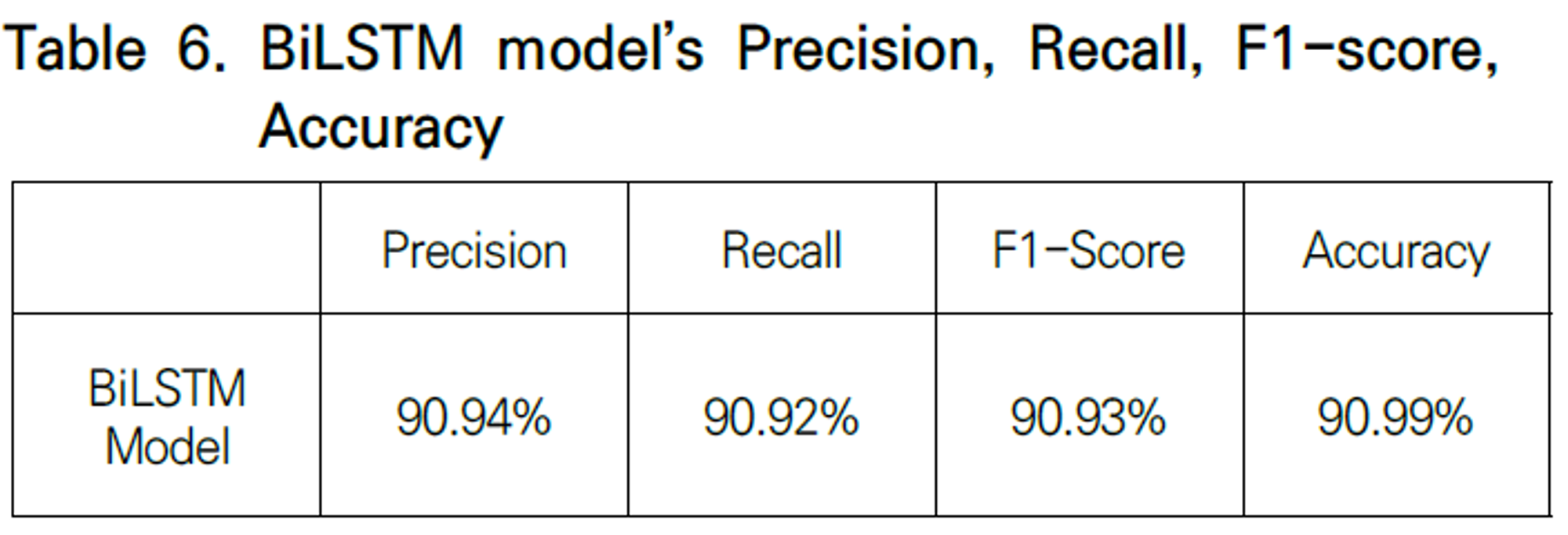
BiLSTM 모델의 전체적인 성능평가
결과 :
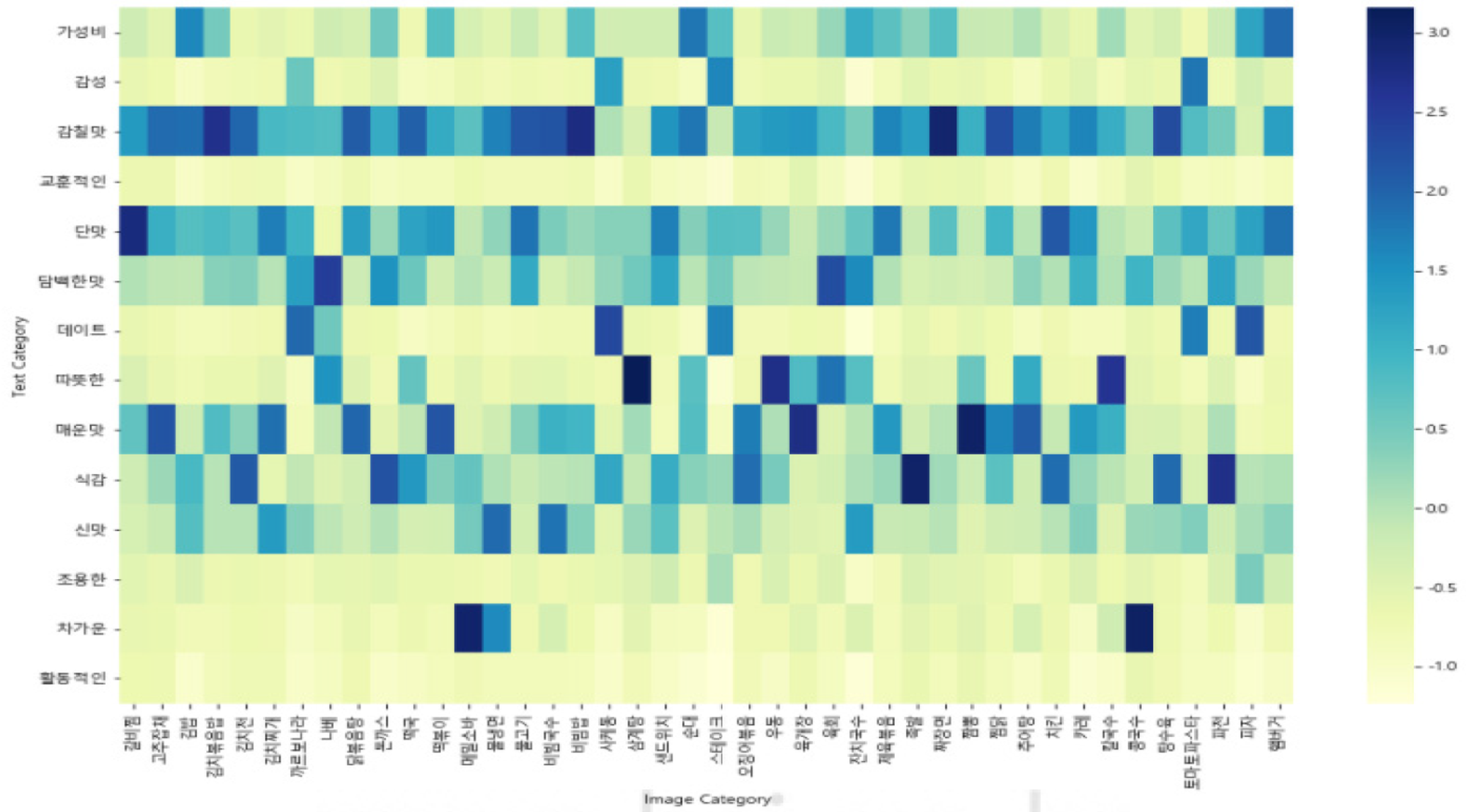
4.2.3 히트맵
SNS 리뷰 분류에서의 개인 성향에 대한 다양성을 확인하기 위해 히트맵을 통해 확인한다.
해당 히트맵은 41,984개의 SNS 리뷰 데이터의 결과 수치를 합산 후 정규화하여 시각화하였다.
결과 :
5. 결론
한계점
•
본 논문에서는 미리 정의한 이미지 카테고리와 텍스트 카테고리의 조합으로만 사용자의 성향을 분류할 수 있다.
•
그래서 일상, 문화 활동 등 다양한 범주의 SNS 게시글을 분석하지 못한다는 한계점이 있다.
향후에는 제안한 방법을 통해 음식뿐만 아니라 영화,패션, 스포츠 등 다양한 분야의 SNS 게시글에 대한 사용자의 성향 분류로 확장된다면 해당 성향 분류를 통한 사용자 맞춤 서비스나 마케팅 등으로 활용될 것으로 기대된다.